
2expres
-
Количество публикаций
102 -
Зарегистрирован
-
Посещение
-
Days Won
3
Сообщения, опубликованные пользователем 2expres
-
-
Распознавание номеров. Практическое пособие. Часть 1 Статья на хабре. Нейросети GPU 500 мс, а CPU 5 сек. Определяет 80% номеров.
-
Закончил программу контурного анализа. Перепробовал множество вариантов. Применял дескрипторы Фурье - получил не очень хороший результат. Оказалось, что примитивные методы работают значительно лучше. Результат меня порадовал. Удалось получить быстрое распознавание любых замкнутых контуров. В качестве базы данных загружаются изображения в виде силуэта эталонных символов. Программа создает базу данных. Один силуэт это 512 байт в базе данных. Силуэты могут быть любые шрифты (Если буква "В", то без двух белых отверстий), предметы, дорожные знаки, силуэты самолетов и т.д.
Тренировался на шрифте. Распознает любой шрифт повернутый до углов 45 градусов при условии совпадения начальных точек. Проблему начальной точки решил за счет того что в базу данных загружаю 2 символа один повернут влево на 20, другой вправо на 20 градусов. Теоретически возможно распознавание под любым углом, но при этом будет увеличиваться время обработки. Пример базы цифр ниже:

Есть определенные проблемы. Я проверяю на похожесть, а не на абсолютное сравнение. Поэтому если я проверяю, какая это цифра, а на проверяемом изображении "каракатица", то программа все равно показывает какую нибудь цифру. Я не знаю, как решить данную проблему. Но зато распознает символы повернутые ,искаженные, с большой изометрией и немного смещенной начальной точкой.
-
12 часа назад, Nuzhny сказал:кажется, что на этом рынке будет сложно конкурировать.
Для меня распознавание номеров представляет чисто академический интерес для проверки своих алгоритмов. Я применяю свой механизм: 1) сегментация 2) векторизация 3) логический и контурный анализ полученных сегментов в векторном виде.для любого распознавания (без применения нейронных сетей). Я просто хочу сравнить подходы, быстродействие.
3 часа назад, Король сказал:Время обработки 500 мс и выше.
Это в одном потоке или у вас производится распараллеливание на несколько ядер?
-
В 11.11.2016 at 14:51, Король сказал:Сделал коллаж картинок как моя программа распознает в переосвещенной области номерного знака, засветки. Чем могу, помогу в написании проекта.
Добрый день! Заинтересовался темой распознавания автомобильных номеров. Пользовался вашей программой показывает на мой взгляд хорошие результаты. Чем отличается ваша бесплатная программа от коммерческого продукта? Сколько времени обрабатывается один кадр (какого разрешения и какой процессор) в коммерческом продукте?
-
Пример использования выделения краев (Соболя):
Осталось найти вертикальные и горизонтальные линии, которых не так уж и много. Могу выполнить данную задачу под ключ.
-
В 31.08.2018 at 14:43, korvintag сказал:Для системы управления складскими роботами необходимо определять погрешности монтажников при варке стеллажей. С этой целью для каждой ячейки делается фото, и сейчас живой человечек рисует в каждом таком фото желтый крестик (см. фото с красным кружочком и зеленым контуром). Пока ячеек было 2-3000, было терпимо. Сейчас планируется робосклад на 100000 ячеек, и решили делать распознавание образов (нужно определить край уголка). Образы могут быть сами разные, в т.ч. с перегороженным куском уголка (см. другие фото). Хотим использовать библиотеку OpenCV (emgucv для C#). Вопрос - в какую сторону копать?
- анализ изображений (выбор отличительных признаков, морфология, поиск контуров, гистограммы)
- или обнаружение объектов, в частности лиц
- или еще что?
Сгодятся ли для этой задачи контуры? Или, из-за игры теней и частичного перекрытия самим роботом, контуры использовать не получится?Еще чисто теоретически задача решаема для дневного освещения? Или только ночью (см. фото в аттаче)?
.thumb.jpg.dac0308fde3bd05000b1ede89d0b4e0b.jpg)
.thumb.jpg.06c17c114895e0b9d47ca60c23d2d1a7.jpg)
.thumb.jpg.357cf898b2cd0274b61fe4af21e825d7.jpg)
.thumb.jpg.3fae9b75ad7ed102fe772c8e3e4aef49.jpg)
Альтернативное предложение не использовать нейронные сети. Выполнить на фотографии поиск прямых линий. Прямая линия не должна превышать некую длину N, равную длине полки уголка. Ищем пересекаются эти линии или они могут пересекаться не превышая длинны N. Производить дополнительную проверку найденных объектов. Для того чтобы найти на этом изображении линии нужна хорошая сегментация изображения, выделение краев.
-
Думаю, в вашем случае, только платный продукт. Вот, например, http://www.mallenom.ru/demo/avtomarshal/
-
Дескрипторы можно сравнивать 2 способами:
1) находим погрешность каждого из дескрипторов, погрешности складываем и сравниваем с порогом. Возможно погрешности возводим в квадрат и суммируем.
2) сравниваем с порогом каждую погрешность и если один из дескрипторов превышает порог, то сравнения нет.
Какой из двух способов верный?
-
1 час назад, Smorodov сказал:Посмотрите здесь:
Количество дескрипторов, задает насколько детально описывается фигура. Подрезание количества коэффициентов дает сглаживание контуров.
Еще тут посмотрите: https://www.codeproject.com/Articles/196168/Contour-Analysis-for-Image-Recognition-in-C
Спасибо, за ответ. Ссылку я уже видел ранее. Именно она вдохновила меня на распознавание шрифтов, но другим способом. В данной ссылке автор Pavel Torgashov применяет 30 элементарных векторов. Я считаю, что даже для шрифта это недостаточно и применяю 128.
У меня всегда любой контур описывается 128 элементарными векторами (ЭВ). Соответственно эталоны так же описаны, как 128 ЭВ. В данном случае максимальное число дескрипторов Фурье может быть 128. Я хочу выбрать 8. Это 6,25%, достаточно ли это распознавания шрифта? Так же не понятно, как сравнивать дескрипторы, какую брать погрешность?
-
Мне предложили делать сравнение сигналов с эталонами не методом перебора, а с помощью дескрипторов Фурье. Дескрипторы сигналов я вычисляю быстро применяя табличные коэффициенты. Дескрипторы эталонов вычисляю заранее.
Сколько необходимо дескрипторов и как их сравнивать на подобие? -
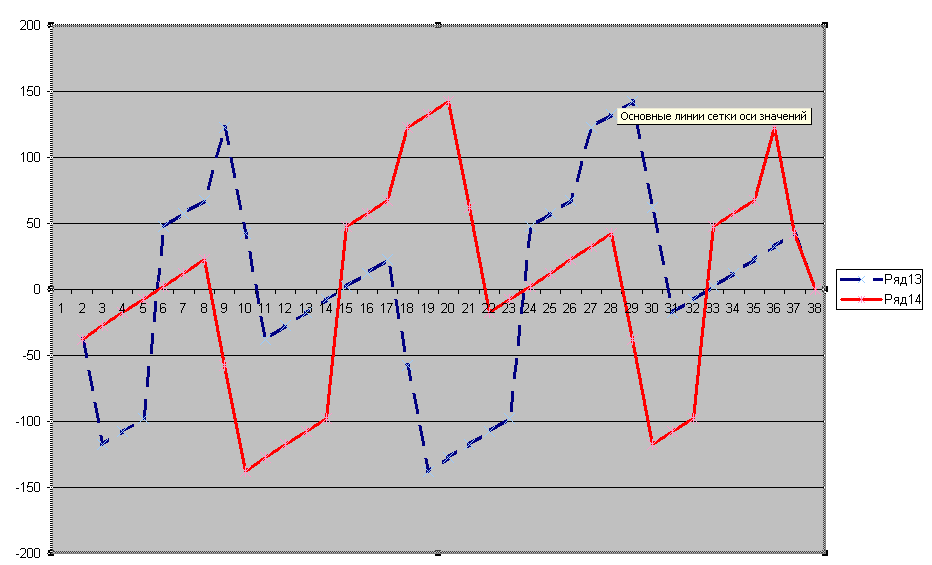
Занимаюсь сравнением объектов методом контурного анализа. Получил 2 периодических последовательности данных, искомый объект и эталон (128 значений последовательности). Последовательность не зависит от местоположения, угла поворота и масштаба. Они отличаются только выбором начальной точки. Если делать сравнение методом перебора, нужно сравнить 128х128 значений. У меня ~3000 контуров в изображении и 200 эталонов. Может кто то знает более быстрый способ совмещения начальных точек или сравнения. График последовательностей на 36 точек представлен ниже, точки периодически повторяются:
-
Много есть способов можно Канни, порог, метод Оцу, сегментация, нейронные сети. Приведенное изображение лучше поможет понять о чем идет речь.
-
Привет! Я правильно понимаю, что это студенческая задача?
Решается она через "порог". Задав значение 67 ты получишь результат, но будет полно мелких сегментов. Тебе нужно или удалить или не считать сегменты размер, которых меньше 400 пикселей. Моя программа удаляет сегменты, результат ниже.

P.S. Число сегментов около 320 шт.
P.P.S. Можешь попробовать порог Оцца и последующую сегментацию.
-
В 06.01.2018 at 23:06, BeS сказал:Для удобства работы с результатами semantic segmentation хочу векторизовать label map. Т.е. у нас есть картинка, где каждому пикселю соответствует номер класса и мы хотим все такие блобы закодировать полигонами, соответствующими границам объектов.
Я преобразую растр в вектор без применения стандартных библиотек: делаю сегментацию, векторизацию методом "жука", аппроксимацию ломанной полученного полигона, получение векторного файла *.svg. Меня интересует вопрос, что Вы будете делать с векторным файлом дальше? Есть ли стандартные методы распознавания векторного полигона? Я нахожусь на стадии распознавания силуэта(полигона).
-
Картинки по этой теме?
-
Привет! Хочу поделится с Вами результатами своей работы по сегментации изображений. Исходные фотографии взяты из статей, стереоизображения произвольные из интернета. За 9 месяцев в графическом редакторе Лубок проведены следующие изменения:
1) Преобразование к палитре цветов. Количество цветов от 2 до 32. Преобразования веду методом медианного среза, преобразую изображение к 256 цветам, затем методом кластеризации 256 цветов привожу к заданному количеству цветов. Подобные преобразования есть в графическом редакторе GIMP и Color quantizer . Gimp выполняет преобразование изображения 24 МП в среднем более 1 минуты, но качество преобразования мне не нравится. Изображение приводится к серым цветам. Более качественное преобразование за счет большого количества ручных настроек выполняет Color quantizer , но время выполнения превышает 15 минут. Наше преобразование по качеству находится между GIMP и Color quantizer и выполняется 0,4 секунды.
2) На основе палитры цветов выполнена сегментация, которую я назвал сегментация медианного среза вначале выполняется преобразование к палитре цветов, а затем сегментация изображения.
3) После сегментации изображения получаю очень большое количество мелких сегментов (на 24 МП фотографии до 2 миллионов сегментов). В Каждом мелком сегменте находятся ближайшие соседи и работает алгоритм присоединения мелких сегментов к более крупным. В программе задается минимальная площадь сегмента от 1 до 500 пикселей. Это позволяет резко сократить количество сегментов. Время сегментации и сокращения количества сегментов для 24 МП фотографии всего менее 3 сек!!!
4) Доработана программа векторизации растровых изображений. В начале мы получаем векторный файл методом "хромого" жука (более подробно об этом методе я напишу статью на хабре), в котором углы между векторами кратны 90 градусов. Описание такого файла получается большим. Для сокращения векторного описания необходимо применять аппроксимацию полученного контура. Аппроксимацию я выполняю ломанной линией. Для дизайнерских работ аппроксимацию необходимо выполнять кривыми Безье, тогда векторное изображение выглядит более эстетично. Но для компьютерного зрения ломанная линия более предпочтительна, потому что проще производить распознавание объектов. После аппроксимации я формирую файл *.svg, который можно просмотреть любым браузером или векторным редактором.
5) Если производить аппроксимацию в чистом виде, каждого сегмента, то между границами сегментов появляются разрывы, особенно при грубой сегментации. Т.к. сегменты аппроксимируются по разному в зависимости от начала сегмента. В моей программе выполняется стыковка границ сегментов, если этот сегмент уже аппроксимирован, то следующий сегмент берет в качестве описания границу ранее описанного сегмента. Этот метод работает, только для 4-х связной сегментации медианного среза.
6) Обработка больших файлов до 8000 х 8000 пикселей. Для обработки больших файлов очень хорошее предложение дал smorodov, делать обработку не каждого пикселя, а через пиксель и строку. В этом случае время выполнения можно сократить в 4 раза. Но мы этого пока не сделали.
Пример 1:

Результат в векторе:
Сегментация ректифицированных стереоизображений:

исходное изображение

сегментация 2 цвета. Минимальный размер сегмента 50

сегментация 4 цвета. Минимальный размер сегмента 50

сегментация 8 цветов. Минимальный размер сегмента 50

сегментация 32 цвета. Минимальный размер сегмента 50
Полученные результаты позволяют получать привязки к сегментам, узнать расстояние до объектов. Время обработки до 65 мс (это одним ядром)- это позволяет производить обработку в реальном масштабе времени 30 кадров в секунду.
Пример, из статьи https://habrahabr.ru/company/intel/blog/266347/ :

исходное изображение

Изображение после сегментации алгоритмом WaterShed полученное в статье

результат полученный в графическом редакторе Лубок. 4-х связная сегментация (6 цветов, мин размер сегмента 500)
В полученном мной результате монеты отделены от фона, многие монеты разделены друг от друга.
-
 1
1
-
-
Результат получили выполнив 2 сегментации: вначале легкую 8-ми связную сегментацию для выравнивания освещенности, затем глубокую сегментацию медианного среза используя разделение по 2 цветам. Программы и алгоритмы полностью наши. Можете сами поиграться с нашей сегментацией http://esm.ho.ua/Automat.html внизу графический редактор Лубок и как им пользоваться для сегментации изображений.
-
 1
1
-
-
2 часа назад, noname сказал:Над четкостью и освещением сейчас работаем.
Немного занимался похожей тематикой: визуальный контроль при производстве печатных плат, если интересно http://esm.ho.ua/Visual.html
Я пришел к выводу, что для получения качественных результатов необходимо: качественная съемка с высоким разрешением и уделить особое внимание освещению печатной платы. Оно должно быть равномерным, без бликов и затемнений. Как вариант использование бестеневых ламп. В исходной фотографии, что по ссылке нет хорошего освещения, но за счет высокого разрешения и четкости все дорожки печатных плат сегментируются. Что Вы можете видеть по результатам сегментации.
-
1
-
-
Спасибо, за оперативный ответ! ppm - файлы действительно обрабатывает, pbm - нет.
-
Прошу помощи не получается запустить исходники http://cs.brown.edu/~pff/segment/
Знаю, много их использовали, но в линуксе не сильно силен. Копирую в папку, после этого выполняю команду <make>. Появляется файл *segment. Запускаю его командой:
./segment 0,5 20 20 /1/segment/test.png /1/segment/test1.png
или
./segment 0,5 20 20 test.png test1.png
Получаю ошибку:
loading input image.
terminate called after throwing an instance of 'pnm_error'
Aborted
Пробовал на 2 системниках CentOS и Debian результат тот же.
-
5 часов назад, videostreamer сказал:при появлении светящихся фонариков на экране
Можно пример видео? Чтобы понять о чем идет речь.
-
4 часа назад, Nuzhny сказал:Да, программирование под видеокарты - это не такое уж простое занятие.
Я с Вами полностью согласен, поэтому хочу понять какие классы задач можно решать GPU.
Если можно решить выше приведенный примитивный пример, то стоит GPU осваивать. На GPU хорошо решаются задачи выделения границ, получил частичку изображения и записал туда же откуда и взял. Это будет на порядки быстрее чем на CPU.
4 часа назад, Nuzhny сказал:можно применить небольшую компрессию
Компрессию и так уже сделали уменьшив разрядность с 24 до 18. Дальнейшие уменьшение разрядности приведет к заметным искажениям. А размер таблицы гистограммы не зависит от размера изображения.
4 часа назад, Nuzhny сказал:в первом kernel одна workgroup будет обрабатывать участок изображения 64х64 и сделает для него не полную гистограмму, а список того, что ей попалось.
Хорошо получаем множества таблицу другого вида, состоящую не из одного значения(количество пикселей данного цвета ), а из двух(номер цвета и количество пикселей). А вот задача получить конечную таблицу будет получить сложнее, чем просто посчитать цвета в изображении. На мой взгляд CPU данную задачу решит быстрее.
-
10 часов назад, iskees сказал:Ваш пример немного не понятен, вы хотите общую гистограмму всего изображение или скользящих окон.
Пример приведен для всего изображения. Да изображение я могу разбить на части и обрабатывать разными процессорами. Но создаваемая таблица размером 1 Мб должна быть доступна для всех процессоров и каждый процессор должен записывать результат непредсказуемо или в начало или в конец или середину этой таблицы. И основное время будет уходить не на вычислительные процессы, а на обращение к памяти. Как можно реализовать по другому?
На CPU я могу прогрузить таблицу в кеш 2 или 3 уровня увеличив быстродействие. Как это реализовать на GPU быстрее, чем на CPU?
-
В 25.07.2017 at 21:20, iskees сказал:на тесле 500*500 пикселей 33мс
Спасибо за ответ.
Разбирал структуру CUDA.
У меня почему то все задачи по компьютерному зрению сводятся к последовательному прохождению каким-либо окном по изображению и составлению таблиц. Последовательное прохождение по изображению хорошо работает с памятью, т.к. непосредственно работаю с кешем. А вот создание таблиц - это кошмар для кеша, если таблица занимает несколько мегабайт памяти. Так как неизвестно в какую область таблицы я перейду на следующем шаге.
Структура CUDA (может я ее не правильно понял) будет отлично работать только для последовательной обработки изображений. Пример, изменение яркости изображения, когда идет последовательная подкачка памяти. А как работать с таблицами в несколько мегабайт? Простейший пример, на мой взгляд неэффективности CUDA: сделать цветную гистограмму изображения(т.е. посчитать количество пикселей каждого цвета). Даже если ограничимся 6 разрядами каждого цвета RGB, итого 18 разрядов. Размер таблицы 1 МегаБайт.
.jpg.783ffec4edcfc0d16fb97581f37c89ed.jpg)
.jpg.73ae60dbc1c62f9e6342064c26ab18c9.jpg)
.jpg.27d1680483eaabc58dcab4e62fcca541.jpg)
.jpg.e81e0cf70b2561f4b4b4c0ecacc6cc27.jpg)

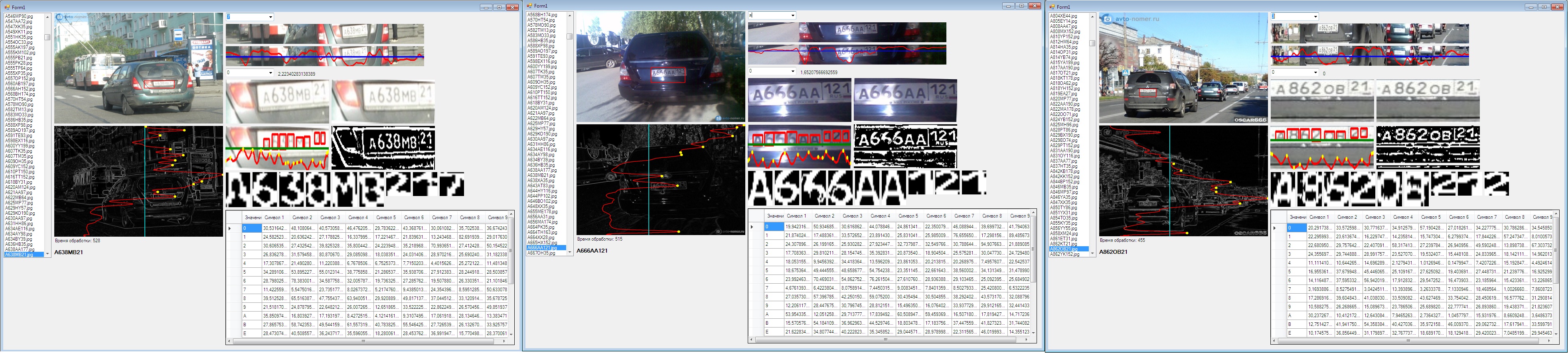
Распознавание номерного знака, расп. текста.
в OpenCV
Опубликовано · Report reply
Решил применить векторный контурный анализ на практике.
Распознавание текста для меня пока сложно, т.к. в реальном тексте символы сливаются друг с другом, и мне тогда все равно какой текст распознавать-печатный или рукописный.
Распознавание авто номеров для меня более простая задача, потому что:
1. Не ищу пластину авто номера.
2. Не вырезаю пластину из изображения.
3. Не выравниваю табличку вместе с символами, если она под углом.
4. Не вырезаю каждый символ.
5. Не масштабирую символы в растре.
6. Не применяю OpenCV и нейронные сети, только свои алгоритмы исключительно на ассемблере.
Мои алгоритмы:
1. Бинаризация изображения. Применяю адаптивный порог.
2. 4-х связная сегментация изображения.
3. Векторизация изображения.
4. Апроксимация векторов.
5. Векторный контурный анализ и сравнение сегментов с базой данных.
Выше перечисленные алгоритмы универсальны и мне остается написать небольшую программку, находящую последовательность символов определенных размеров. Используется только таблица сегментов, поэтому это не занимает время.
Основное время уходит на бинаризацию, сегментацию, векторизацию изображения. Хорошей бинаризации я не получил, за один раз получаю 3 размывки окнами 9x9,17x9 и 17x17, затем бинаризирую 7 раз с разными порогами и окнами размывки, и 7 раз выше перечисленные алгоритмы, пока не определяю номер.
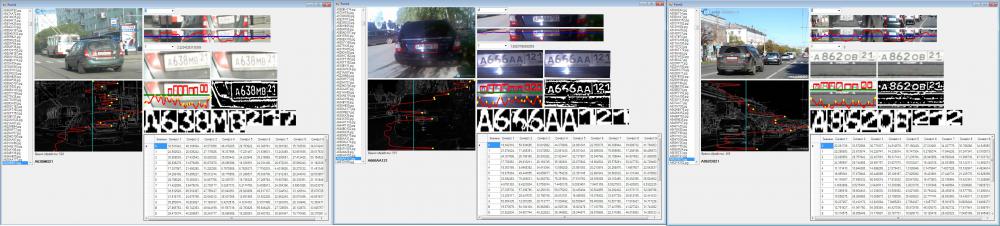
Определение номеров можно посмотреть в моем фото редакторе lubok.exe (150 кб вместе с базами данных). Ограничения: процессор с поддержкой SSE2, lubok.exe только в отдельной папке с базами данных, путь папки с lubok.exe не должен содержать кириллицы - руки не дошли исправить, для изображений таких ограничений нет.
Переключая Вперед Назад переходим к следующему фото. Как сегментировался символ можно посмотреть, нажав- Сегментация - Выбор сегмента. Для бинаризации выбрать: Эффекты - Гравюра. Работает Помощь. Для получения статистики можно запустить определение номеров в папке. Если в папке очень много фото, процесс займет продолжительное время (1,5 минуты на 1000 изображений 600х800, пока не организовал многопоточный режим, все выполняется одним ядром).
Для отладки программы очень помогла подборка фото, предоставленная
Авто номера совпадают с названием файла, поэтому легко сделать авто статистику. Процент правильного определения 95,4%, не видит номер 0,15%, один "глюк" на 5472 фото.
Буду рад замечаниям и конструктивной критике, т.к. работа еще не завершена, хочу получить 98% на этой папке. Так же у кого есть свои подборки фото с автомобилями прошу поделиться.
Папка с фото автомобилей.
Новая версия программы Лубок с функцией определения российских автономеров.