
prim.ko
-
Количество публикаций
42 -
Зарегистрирован
-
Посещение
-
Days Won
2
Сообщения, опубликованные пользователем prim.ko
-
-
Добрый день. Товарищи, кто сможет поделиться аккаунтом на https://www.cityscapes-dataset.com/login/ для скачивания датасета? Мне уже 2 недели не отвечают по двум заявкам.
-
Так, ну вроде бы похоже на правду. Установил проверку на выход предсказания равному кол-ву классов, то есть 5 и пока работает вроде:
if bottom[0].count != 5*bottom[1].countНе гуд вот, что:
DIGITS не визуализирует отрицательную ошибку на графике:
-
День добрый. Возникло желание прикрутить к caffe Jaccard index: Jaccard
Тренирую сеть для задачи семантической сегментации, используя датасет с 5 классами.
Непременно нужно прикрутить jaccard в python layer. Для этих целей я переделал код, который реализует dice loss: https://github.com/NVIDIA/DIGITS/tree/digits-5.0/examples/medical-imaging
Получается, что я не совсем понимаю как устроены блобы в Caffe. Есть подозрение, что необходимо по-другому передавать axis, при суммировании всех предсказаний и масок:
def forward(self, bottom, top): smooth = 1e-12 label = bottom[1].data[:,0,:,:] # compute prediction prediction = np.argmax(bottom[0].data, axis=1) # area of predicted contour a_p = np.sum(prediction, axis=self.sum_axes) # area of contour in label a_l = np.sum(label, axis=self.sum_axes) # area of intersection a_pl = np.sum(prediction * label, axis=self.sum_axes) # dice coefficient dice_coeff = np.mean((2.*a_pl+smooth)/(a_p + a_l+smooth)) top[0].data[...] = dice_coeff
Получилась следующая реализация:
import random import numpy as np import caffe import math class Jaccard(caffe.Layer): """ A layer that calculates the Jaccard coefficient """ def setup(self, bottom, top): if len(bottom) != 2: raise Exception("Need two inputs to compute Jaccard coefficient.") # compute sum over all axes but the batch and channel axes self.sum_axes = tuple(range(1, bottom[0].data.ndim - 1)) def reshape(self, bottom, top): # check input dimensions match if bottom[0].count != 2*bottom[1].count: raise Exception("Prediction must have twice the number of elements of the input.") # loss output is scalar top[0].reshape(1) def forward(self, bottom, top): smooth = 1e-12 label = bottom[1].data[:,0,:,:] # compute prediction prediction = np.argmax(bottom[0].data, axis=1) # area of predicted contour a_p = np.sum(prediction, axis=self.sum_axes) # area of contour in label a_l = np.sum(label, axis=self.sum_axes) # area of intersection a_pl = np.sum(prediction * label, axis=self.sum_axes) # jaccard coef jaccard_coef = np.mean((a_pl+smooth) / (a_p + a_l - a_pl + smooth)) jaccard_coef=0 top[0].data[...] = jaccard_coef def backward(self, top, propagate_down, bottom): if propagate_down[1]: raise Exception("label not diff") elif propagate_down[0]: #crossentropy loss_crossentropy = 0 for i in range(len(prediction)): loss_crossentropy = loss_crossentropy - prediction[i] * (label[i] - (prediction[i] >= 0)) - math.log(1 + math.exp(prediction[i] - 2 * prediction[i] * (prediction[i] >= 0))) bottom[0].diff[...] = -(math.log(jaccard_coef) + loss_crossentropy) else: raise Exception("no diff")
Код ошибки error code 1. Если установить кол-во классов равное 2 и использовать код dice loss из вышеприведенной ссылки, все прекрасно заходит. Ошибка в индексах. Есть какие-нибудь соображения?
-
-
7 минут назад, Smorodov сказал:Хотел еще повороты приделать но питонский слой
На этот счет хочу еще проверить возможно ли будет загружать несколько классов в один модуль, используя один файл, но несколько python layers. Удобно для ошибки и data test aug будет использовать
-
Интересная сетка. Для сегментации? С какой целью делаются множественные crop?
-
То есть подход следующий, я правильно понял?
1) загружаем веса2) Изменяем свою сеть. Объявляем столько слоев из прототипа модели VGG-16 сколько необходимо, в своем прототипе модели. Вот на этом моменте замораживаем добавленные слои. Здесь попрошу подробнее разъяснить. Свои слои при этом выбрасываются? Оставляются только выходы из своей модели?
3) Получили необходимый loss, возвращаем все слои на место?
-
1 час назад, Smorodov сказал:Он прогрузит все слои которые имеют то же имя что и в caffemodel файле
При этом память GPU больше потребляется, в отличие от обучения своей сеткой с нуля? В Keras понравилось, что мы предсказываем с VGG-16 в отдельной итерации на трогая память GPU. А тут как?
-
53 минуты назад, Smorodov сказал:Не, дохлый номер, ошибка 1 ушла, теперь ошибка -6. Чего-то я здесь недопонимаю.
В digits зашло без ошибок
-
Добрый вечер. Интересует как можно обучить модель с использованием vgg-16 предобученной? В keras это как говорит @ternaus из ods "делается мизинцем левой ноги". Причем вообще не глядя в монитор. https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html .
А для Caffe можно так же просто? Интуитивно догадываюсь, что нужно как-то замораживать слои все сверточные и обучать только выход. И еще, например входы vgg-16 224*244*3. Моя сетка запрашивает на вход изображение 256*256. Изменять свою сеть?
-
error 1 всегда преследует созданный пользователем python файл. В данном случае функцию doAugmentation лучше поместить в класс RotationLayer
import random import numpy as np import caffe class RotationLayer(caffe.Layer): def setup(self, bottom, top): print('In Setup') #assert len(bottom) == 2, 'requires 2 layer.bottom' #assert bottom[0].data.ndim >= 3, 'requires image data' #assert bottom[1].data.ndim >= 3, 'requires image data' #assert len(top) == 2, 'requires 2 layer.top' def reshape(self, bottom, top): # Copy shape from bottom print('In Reshape') #top[0].reshape(*bottom[0].data.shape) #top[1].reshape(*bottom[1].data.shape) def forward(self, bottom, top): # Copy all of the data print('In Forward') #top[0].data[...] = bottom[0].data[...] #top[1].data[...] = bottom[1].data[...] #for ii in xrange(0, top[0].data.shape[0]): # [top[0].data[ii, :, :, :],top[1].data[ii, :, :, :]] = doAugmentation(top[0].data[ii, :, :, :],top[1].data[ii, :, :, :]) def backward(self, top, propagate_down, bottom): pass def doAugmentation(self): print("aug") #print('In Augmentation') #ang=random.uniform(-30,30) #return [ndimage.rotate(img, ang, reshape=False),ndimage.rotate(mask, ang, reshape=False)]
Если используешь DIGITS в определении модели можно указать module: "digits_python_layers"
-
12 часа назад, mrgloom сказал:Напишите про опыт с TensoRT.
Есть замечательный туториал по работе с TensorRT и внутренней камерой jetsona. Там работает все без унылой OpenCV - на gstremer`e вытягивается сразу на GPU. Перепилил код под свои нужды и все замечательно. DetectNet к примеру на 2 класса выдает - 15 fps (480*360)
https://github.com/dusty-nv/jetson-inference#image-segmentation-with-segnet -
13 минуты назад, mrgloom сказал:А что такое TX* ? Tegra?
Ну так python layer придётся переписать на C++/Cuda он же вроде только для train годится.
Да. Jetson TX. Если не вру, то python layer вообще не участвует в deploy
-
15 часов назад, mrgloom сказал:Ну так а если использовать python layer, то почему caffe?
Softmax по идее можно взвесить.
Но может у них опять же кастомный layer для этого.
Ага, помню когда я взвешивал выборку camvid, в которой 325 картинок. , ну она еще с segnet идет в комплексе, получились немного другие цифры ежели у автора. Там даже issue открыли в git, в котором у народа такие же цифры вышли. Автор молчит:)
Некоторые цифры в классах на порядок отличались.
Caffè - потому что она единственная собирается без боли под TX*. К тому же есть TensoRT, которые вообще песня:)
-
3 часа назад, mrgloom сказал:По идее и без BN должно работать, на график сходимости интересно посмотреть с и без.
У меня выборка большая. Настроить BN было принципиально.
Не знаю как обстоят дела с caffe, которую собирать ручками, в dockere так.
Dice loss прикрутил. Довольно удобно оказалось, что можно юзать python layer. С ним другое дело. Стандартный softmaxwithloss грустно относится к неравномерно распределеным классам.
-
В общем через боль, страдания, подбор параметров и еще танцев с бубном проблема решена. Надеюсь кому-то поможет эта информация.
Почему-то по умолчанию в DIGITS ( использовал docker nvidia-digits-rc-6.0) в слое типа BatchNorm ( а может быть и в других слоях ) используется CUDNN engine в противовес CAFFE engine, если этого не задавать явно. Мужики пишут по этому поводу вот что:
ЦитатаTop and bottom blobs need to be different for engine:CUDNN BatchNorm. This constraint is not there for engine:CAFFE BatchNorm. This is the reason for non-convergence.
Теперь Caffe BN слой для использования его в DIGITS выглядит вот так:
layer { name: "G9_d2_bn" type: "BatchNorm" bottom: "G9_d1_conv" top: "G9_d2_bn" param { #scale lr_mult: 1 decay_mult: 1 } param { #shift/bias lr_mult: 1 decay_mult: 1 } param { #global mean lr_mult: 0 decay_mult: 0 } param { #global var lr_mult: 0 decay_mult: 0 } batch_norm_param { scale_filler { type: "constant" value: 1 } bias_filler { type: "constant" value: 0 } engine: CUDNN use_global_stats: false } }Интересно, что при использовании CUDNN engine память gpu отжирается вот так:
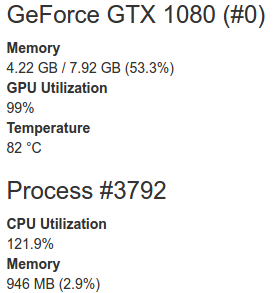
Если установить CAFFE engine:
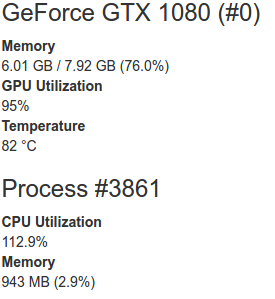
За одинаковое время обучения сеть с использованием CUDNN engine заврешила 15 эпох. С использованием CAFFE engine 7 эпох.
-
 1
1
-
-
Та модель, которую обучил - без bn. В keras я пробовал изменять модель после того как обучил. Добавлял слои и загружал веса от старой - так нельзя. В Caffè ведь так же
-
12 минуты назад, mrgloom сказал:Еще в dice loss есть некий smooth parameter, по идее это же может быть просто что типа eps=1e-3, чтобы не было деления на 0 или это как то влияет на предсказание границ?
При изменении данного параметра я никаких сдвигов не увидел. Я использовал 1е-6.
12 минуты назад, mrgloom сказал:Можно попробовать learning rate поменьше имея уже предобученную модель.
У меня нет предобученной модели. Или речь идет например о VGG-16? Это возможно сюда прикрутить чтобы не обучаться с ноля? И поможет ли это в данном случае, ведь картинки спутниковые, а ImageNet содержит совсем другие классы. Опять таки почему с BN не работает?) Мало 70 эпох?
-
40 минут назад, mrgloom сказал:lr_mult: 0 типо фризит лайер т.е. сеть не учится.
Ясно. Значит можно просто установить размер батча равным 12 и не указывать "accumulation".
Вообщем моя ошибка - поучил сеть 10 эпох и бежал смотреть вывод. По этому ничего и не показывала. Убрал все BN и поучил 70 эпох (600 картинок) вывод получил. Значит сеть учится. Но только почему с BN не учится? Установил даже lr_mult=1, decay_mult=1
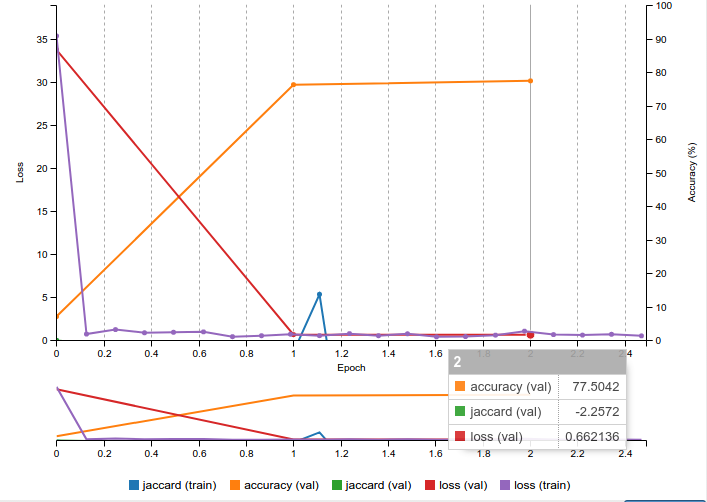
Есть вопрос у меня еще по поводу функции активации. в оригинальном U-NET использовали dice loss либо jackard. Как возможно сюда это запилить?
Получается глупая картинка при обучении:
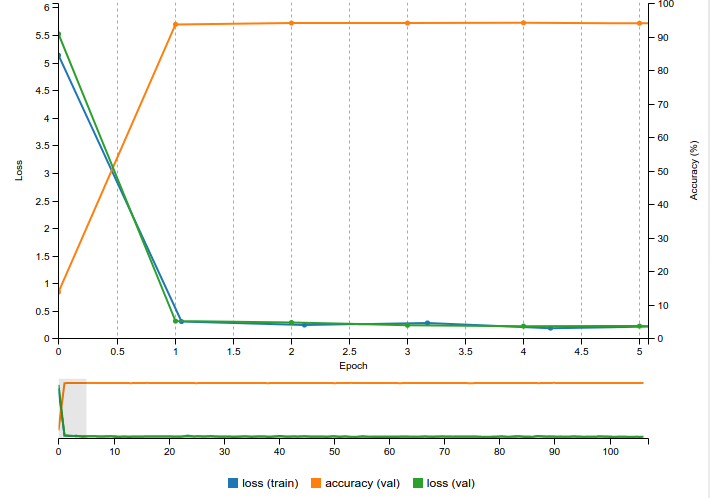
После первой эпохи accuracy достигает 0.94 и так и держится чуть-чуть (+- 0.001) изменяясь.
Тут явно какой-то криминал. Последние слои сделал вот так:
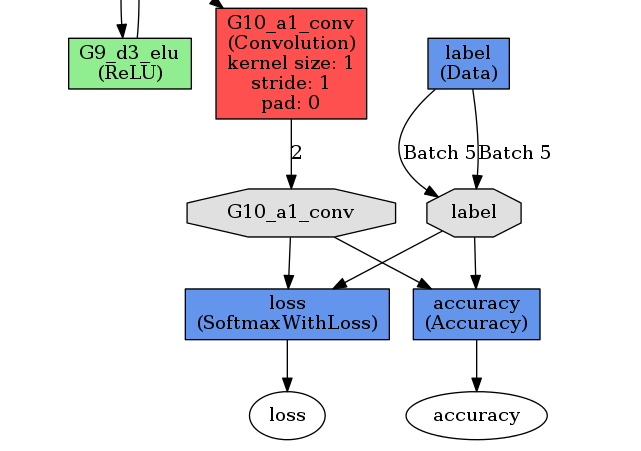
layer { name: "G10_a1_conv" type: "Convolution" bottom: "G9_d1_conv" top: "G10_a1_conv" convolution_param { num_output: 2 kernel_size: 1 pad: 0 engine: CUDNN weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "G10_a1_conv" bottom: "label" top: "loss" loss_param { normalize: true } exclude { stage: "deploy" } } layer { name: "accuracy" type: "Accuracy" bottom: "G10_a1_conv" bottom: "label" top: "accuracy" include { stage: "val" } }Есть предположения в чем может быть дело?
-
11 час назад, mrgloom сказал:Нормализовать инпут надо обязательно как zero mean unit vairance, говорят что можно batchnorm запихнуть сразу после инпута.
По картинкам видно что активации нет на следующих слоях, попробуйте learning rate уменьшить или batch size увеличить, еще в caffe + DIGITS можно делать batch accumulation если по памяти не влезает.
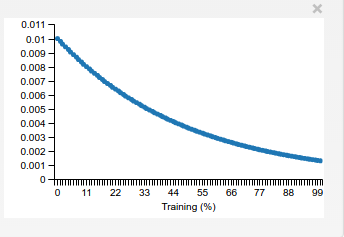
Как это делается примерно? learning rate стоит изначально на 0.01 затем уменьшается с exponential Decay
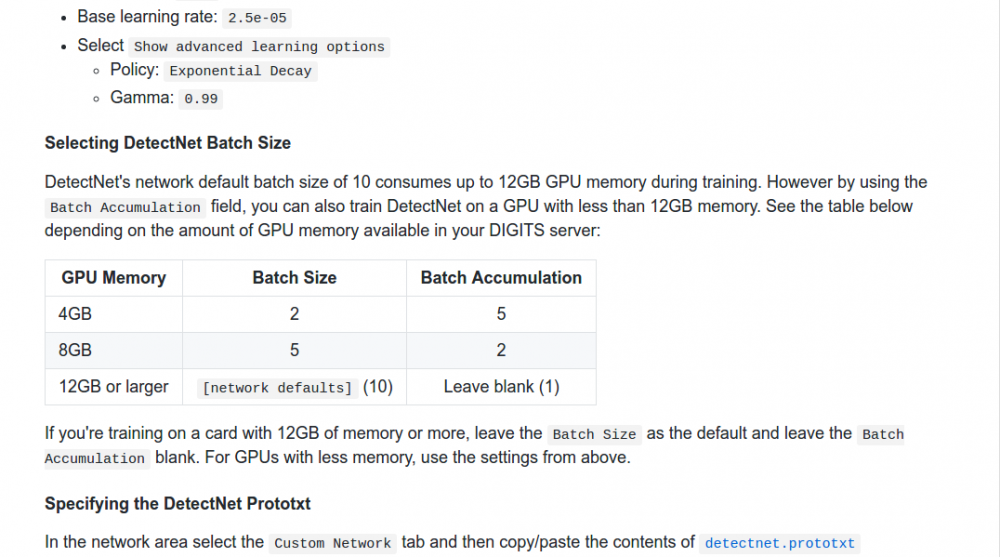
А про batch accumulation ребята вот что пишут на примере detectnet. На 1080 влазит размер батча 12 (картинки 256*256). По совету ребят вроде как нужно не больше единицы установить
 10 часов назад, Smorodov сказал:
10 часов назад, Smorodov сказал:А родители скорости обучения равные нулям , это так и задумано?
param {
lr_mult: 0
decay_mult: 0
}Эти параметры не знал вообще что делают. Для чего их предназначение?
-
Вроде как заработало, если исправить у последнего сверточного слоя "G10_a1_conv" параметр pad=0. В итоге вышла вот такая U-Net unet_train_new.prototxt . Вот только обучаться это чудо не хочет. Показывает при тестировании белые изображения.

Причем при просмотре статистики Infer One Image.html только первый сверточный слой активируется нормально, а затем вообще ничего. Может это связано с вычитанием среднего?
-
2 часа назад, mrgloom сказал:num_output: 32У вас 32 класса?
А так в DIGITS же можно смотреть активации для всех блобов, по крайней мере для классификации.
И вы загрузку данных как в каком примере используете?
https://github.com/NVIDIA/DIGITS/tree/master/examples/binary-segmentation
https://github.com/NVIDIA/DIGITS/tree/master/examples/medical-imaging
https://github.com/NVIDIA/DIGITS/tree/master/examples/semantic-segmentation
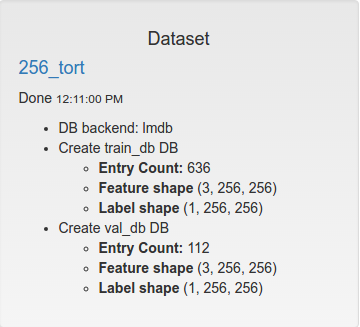
Использовал что-то похожее на https://github.com/NVIDIA/DIGITS/tree/master/examples/semantic-segmentation.
Сконструировал всю сетку unet_train_new.prototxt . DIGITS ругается:
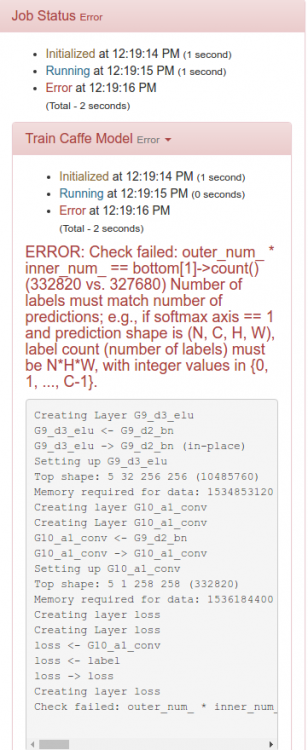
Подаю ему вот такие данные:
Не до конца понял, чего ему не нравится?

-
1 час назад, mrgloom сказал:Тишина всмысле не обучается? В DIGITS там какой то баг был с BatchNorm, всмысле nvidia-caffe ветка, так что лучше использовать caffe-master.
Еще загрузку данных бы неплохо проверить, вы от какого примера отталкивались?
А где у вас Upsampling layer или вы сейчас с уменьшенными масками учите?
Да, не обучается.
Строю сетку и смотрю, на что caffe ругается. Пока не добавил Deconvolution layer.
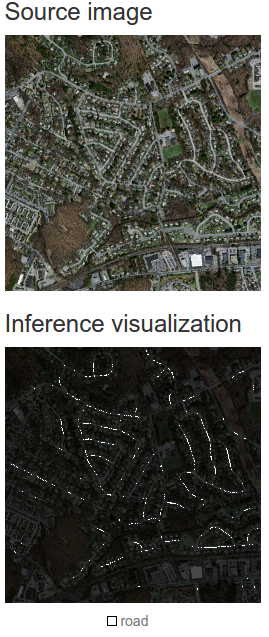
Добавил в модель слой deconv и accuracy и все заработало. Только конечно при тестировании обученной модели показывает темное изображение. выход не правильный?
layer { name: "conv1a" type: "Convolution" bottom: "data" top: "conv1a" convolution_param { num_output: 32 kernel_size: 3 pad: 1 stride: 1 engine: CUDNN weight_filler { type: "xavier" #std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "conv1a_BN" type: "BatchNorm" bottom: "conv1a" top: "conv1a_BN" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } batch_norm_param { use_global_stats: false moving_average_fraction: 0.95 } } layer { name: "elu1" type: "ELU" elu_param { alpha: 1.0} bottom: "conv1a_BN" top: "conv1a_BN" } layer { name: "conv1b" type: "Convolution" bottom: "conv1a_BN" top: "conv1b" convolution_param { num_output: 32 kernel_size: 3 pad: 1 stride: 1 engine: CUDNN weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "conv1b_BN" type: "BatchNorm" bottom: "conv1b" top: "conv1b_BN" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } batch_norm_param { use_global_stats: false moving_average_fraction: 0.95 } } layer { name: "elu2" type: "ELU" elu_param { alpha: 1.0} bottom: "conv1b_BN" top: "conv1b_BN" } layer { name: "pool1" type: "Pooling" bottom: "conv1b_BN" top: "pool1" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layer { name: "up_deconv1" type: "Deconvolution" bottom: "pool1" top: "up_deconv1" param { lr_mult: 1 decay_mult: 1 } convolution_param { num_output: 32 kernel_size: 2 stride: 2 } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "up_deconv1" bottom: "label" top: "loss" include: { phase: TRAIN } } layer { name: "accuracy" type: "Accuracy" bottom: "up_deconv1" bottom: "label" top: "accuracy" include { stage: "val" } }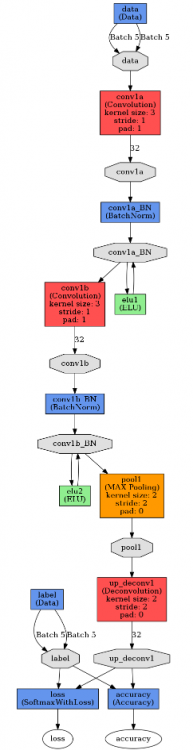
-
1 час назад, mrgloom сказал:Можно поподробней что после U-net происходит? плотности чего? монте-карло для чего?
По монте-карло все просто:
Имеем карту мира( например бинарную карту на которой отмечены дома ). Переводим карту в матрицу вероятностей. Снимаем далее показания с сенсора (камеры в моем случае), сегментируем и рассчитываем вероятность пребывания в какой либо точке на карте используя эту матрицу вероятностей. Затем берем следующее показание сенсора (следующий кадр) и при помощи лукаса-канаде вычисляем корреляцию. Это будет значением, на которое мы сдвинулись. Снова рассчитываем вероятности, которые в этот раз изменятся. Чем выше вероятность какой либо точки - значит выше вероятность нашего там пребывания.
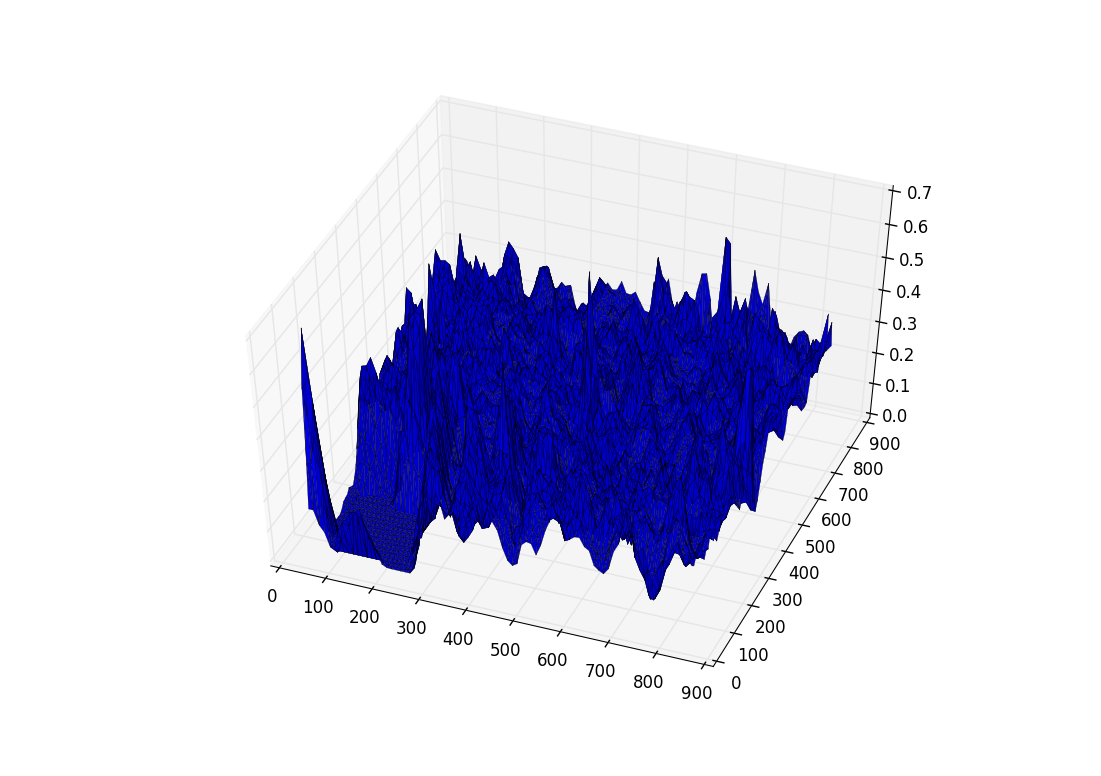
В качестве самого простого способа можно тупо брать значение центрального пикселя сегментированного изображения и подавать это значение в монте-карло, но это долго. Потому что если генерировать матрицу вероятностей ( то что является нашим миром) из всех пикселей карты-подложки - это будет очень медленно. Представь у тебя карта-подложка размером 10к*10к пикселей = 100000000 матрица. И при каждом новом показании сенсора (камеры) тебе это все просчитывать. Поэтому нужна какая-то метрика, описывающая объекты на карте-подложке (здания). Тут я использую метод непараметрического восстановления плотности. По всей карте-подложке рассчитываем центры масс зданий и применяем куполообразную функцию, что-то типо:
@staticmethod def nonparametric_estimation(points, x_grid, y_grid, x_size, y_size): """ :param points: array of points (center of mass) :param x_grid: coordinate x of grid :param y_grid: coordinate y of grid :param x_size: window size :param y_size: windows size :return: """ def f(z): if math.fabs(z) < 1: return 1 - math.fabs(z) else: return 0 value = 0 count = 0 for i in range(len(points)): if math.fabs(x_grid - points[i][0]) < x_size and math.fabs(y_grid - points[i][1]) < y_size: value += f((x_grid - points[i][0]) / x_size) * f((y_grid - points[i][1]) / y_size) count += 1 if count > 0: return value / count else: return 0
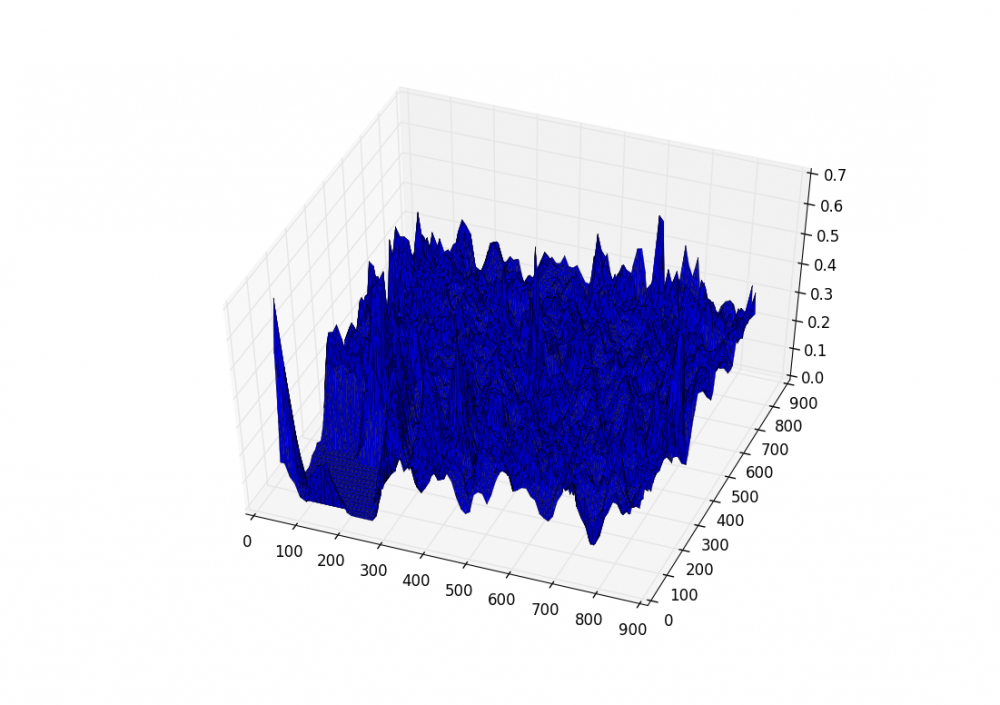
Это необходимо для того чтобы уменьшить размер матрицы вероятностей. Тут зависит от шага, с которым будем рассчитывать плотность. Я использовал шаг 5 пикселей. Только например, если БЛА летит на высоте 900м, а карта-подложка была сделана с 500 метров, в этом случае нужно кропать изображение до размера с которым рассчитывались значения плотностей.
Получается вот такая красивая картинка для изображения:





Афинные преобразования в трехмерном пространстве
в OpenCV
Опубликовано · Report reply
Добрый день. Не совсем ясна одна вещь, связанная с преобразованием изображений. К примеру имеется изображение, полученное камерой. Камера внизсмотрящая. Известно положение камеры в мировом пространстве. Их однозначно определяет акселерометр. Мне необходимо воспользоваться данными с акселерометра для афинных преобразований полученного изображения.
Как я понял для этого необходимо перевести координаты двумерных точек на изображении в однородные координаты [x,y]-> [x,y,1], и умножить вектор на матрицу поворота. Необходимо ли где-то использовать матрицу внутренних параметров камеры?
В конечном итоге необходимо откорректировать проекцию изображения.