
Pechkin80
-
Количество публикаций
72 -
Зарегистрирован
-
Посещение
-
Days Won
1
Сообщения, опубликованные пользователем Pechkin80
-
-
7 минут назад, Nuzhny сказал:На джетсоне, если ты имеешь в виду Nano, всё должно быть иначе, потому что на нём нет выделенной видеопамяти, она общая системная.
Ну и его использовать можно иначе: подключать не ip камеру, а веб или промышленную, получать с неё сразу несжатое видео.
Спасибо. с пайплайном почти разобрался. Еслибы ещё входной и выходной тензор у тф научился бы окунать в gpu, то былобы вообще супер.
-
6 минут назад, Nuzhny сказал:У меня их несколько и все из этого списка
А на джетсоне они тоже из этого сиска ?
-
А видеокарта какая у тебя ?
Моей (940М) тупо нет в списке https://developer.nvidia.com/video-encode-decode-gpu-support-matrix#Decoder
-
const char * imagefilename = "Image_paint.jpg"; static AVFormatContext *fmt_ctx = nullptr; static AVCodecContext *dec_ctx = nullptr; static int video_stream_index = -1; static int open_input_file(const char *filename = videofilename) { /* avcodec_register_all(); AVCodec* codec = avcodec_find_decoder_by_name("mpeg4_cuvid"); AVCodecContext * avctx = avcodec_alloc_context3(codec); avctx->pix_fmt = AV_PIX_FMT_CUDA; */ int ret; AVCodec *dec; if ((ret = avformat_open_input(&fmt_ctx, filename, NULL, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot open input file\n"); return ret; } if ((ret = avformat_find_stream_info(fmt_ctx, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot find stream information\n"); return ret; } /* select the video stream */ ret = av_find_best_stream(fmt_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, &dec, 0); if (ret < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot find a video stream in the input file\n"); return ret; } video_stream_index = ret; dec_ctx = fmt_ctx->streams[video_stream_index]->codec; av_opt_set_int(dec_ctx, "refcounted_frames", 1, 0); std::cout << avcodec_get_name(fmt_ctx->streams[video_stream_index]->codecpar->codec_id) << ": " << fmt_ctx->streams[video_stream_index]->codecpar->codec_id << std::endl; avcodec_register_all(); AVCodec* codec = avcodec_find_decoder_by_name("mpeg4_cuvid"); if (codec != nullptr) { std::cout << "codec found" << std::endl; } fmt_ctx->streams[video_stream_index]->codecpar->codec_id = codec->id; fmt_ctx->streams[video_stream_index]->id = codec->id; fmt_ctx->streams[video_stream_index]->codecpar->codec_type = codec->type; //fmt_ctx->streams[video_stream_index]->codecpar->format = *codec->pix_fmts; fmt_ctx->streams[video_stream_index]->codec->codec_id = codec->id; fmt_ctx->streams[video_stream_index]->codec->codec_type = codec->type; fmt_ctx->streams[video_stream_index]->codecpar->format = AV_PIX_FMT_CUDA; dec_ctx = fmt_ctx->streams[video_stream_index]->codec; dec_ctx->pix_fmt = AV_PIX_FMT_CUDA; ret = av_find_best_stream(fmt_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, &dec, 0); std::cout << avcodec_get_name(fmt_ctx->streams[video_stream_index]->codecpar->codec_id) << ": " << fmt_ctx->streams[video_stream_index]->codecpar->codec_id << std::endl; //AVCodecContext * avctx = avcodec_alloc_context3(codec); //dec_ctx = avctx; //dec = codec; //avctx->pix_fmt = AV_PIX_FMT_CUDA; //if (avcodec_open2(avctx, codec, opts) < 0) // return; /* init the video decoder */ if ((ret = avcodec_open2(dec_ctx, dec, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot open video decoder\n"); return ret; } AVFrame *mpDecodedFrame = av_frame_alloc(); int got; AVPacket tsPkt; av_init_packet(&tsPkt); avcodec_decode_video2(dec_ctx, mpDecodedFrame, &got, &tsPkt); return 0; }
Вот так исполняется без ошибок, но надо понять как реализовать считывание кадра за кадром, и вдобавок как сделать перемотку назад.
-
31 минуту назад, Nuzhny сказал:Я за точку старта брал код для работы с ffmpeg из OpenCV, потому что точно знаю, что он работает. Вариант не идеальный, но, повторюсь, рабочий.
Кстати, проверь для видео стрима, который ты получил, что он правильный:
std::cout << avcodec_get_name(stream->codecpar->codec_id) << ": " << stream->codecpar->codec_id << std::endl;Вообще, программировать с ffmpeg то ещё удовольствие, документация так себе, до правильного ответа приходится доходить чуть ли не методом тыка. Я не уверен, что всё делал правильно, но оно заработало. Эталонный вариант типа ffplay очень сложен: много тысяч строк в одном файле, всё смешано, куча goto.
У меня нет переменной stream в коде.
Код:
std::cout << avcodec_get_name(fmt_ctx->streams[video_stream_index]->codecpar->codec_id) << ": " << fmt_ctx->streams[video_stream_index]->codecpar->codec_id << std::endl;
Выдаёт:
mpeg4: 13
Сама структура ...->streams[video_stream_index]->codec; определена как деприкейтед и на замену предлогают
streams[video_stream_index]->codecpar
-
5 минут назад, 2expres сказал:Я использовал dxva2. Работает и с потоком и с файлами h264. Ты сам собирал ffmpeg или брал готовую сборку?
сам собирал.
-
В 2/5/2019 at 14:14, Nuzhny сказал:Получать можно в том же ffmpeg:
1. Если не собран, то собрать ffmpeg с поддержкой cuvid. Проверка: ./ffmpeg -hwaccels
2. При создании AVCodec вызвать avcodec_find_decoder_by_name("h264_cuvid") или avcodec_find_decoder_by_name("mjpeg_cuvid").
3. Перед вызовом avcodec_decode_video2 устанавливать decCtx->pix_fmt = AV_PIX_FMT_CUDA
4. Тут уже нам возвращают указатель на видеопамять в AVFrame, можно копировать её к себе и обрабатывать:
4.1. Учитываем, что в данном случае у нас кадр не YUV420, а NV12: cudaMemcpy(data, picture->data[0], height * picture->linesize[0], cudaMemcpyDefault)
4.2. Хочется RGB? Вызываем nppiNV12ToBGR_709HDTV_8u_P2C3R
4.3. Хочется засунуть в OpenCV? Вот: cv::cuda::GpuMat* gpuFrame = new cv::cuda::GpuMat(height, width, CV_8UC1, picture->data[0], picture->linesize[0])
Выгрузить из GPU memory и сохранить? Вот: cv::Mat frame; gpuFrame->download(frame);
4.4. Хочется отобразить кадр без копирования в ОЗУ? Создаём OpenGL окно: cv::namedWindow("wnd name", cv::WINDOW_OPENGL)
Это про декодирование на CUDA и обработку кадра средствами OpenCV без копирования в системную память.
Про TensorFlow: тут надо использовать С++ API, на Питончике такой возможности нет. Добавили такую возможность недавно в версии 1.12: вот обсуждение.
Дошли руки попробовать, но тут не сказано как это должно быть связано с загрузкой видеофайла или захвата видеопотока.
Моя попытка успехом не увенчалась:
static AVFormatContext *fmt_ctx = nullptr; static AVCodecContext *dec_ctx = nullptr; static int video_stream_index = -1; static int open_input_file(const char *filename = videofilename) { int ret; AVCodec *dec; if ((ret = avformat_open_input(&fmt_ctx, filename, NULL, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot open input file\n"); return ret; } if ((ret = avformat_find_stream_info(fmt_ctx, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot find stream information\n"); return ret; } /* select the video stream */ ret = av_find_best_stream(fmt_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, &dec, 0); if (ret < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot find a video stream in the input file\n"); return ret; } video_stream_index = ret; dec_ctx = fmt_ctx->streams[video_stream_index]->codec; av_opt_set_int(dec_ctx, "refcounted_frames", 1, 0); avcodec_register_all(); AVCodec* codec = avcodec_find_decoder_by_name("h264_cuvid"); AVCodecContext * avctx = avcodec_alloc_context3(codec); dec_ctx = avctx; dec = codec; avctx->pix_fmt = AV_PIX_FMT_CUDA; //if (avcodec_open2(avctx, codec, opts) < 0) // return; /* init the video decoder */ if ((ret = avcodec_open2(dec_ctx, dec, NULL)) < 0) { av_log(NULL, AV_LOG_ERROR, "Cannot open video decoder\n"); return ret; } return 0; }
Вывод приложения:
Цитата[h264_cuvid @ 0x55fefb78a440] Codec h264_cuvid is not supported.
Cannot open video decoder
Вывод утилиты:
Цитата(base) user@aspire:/opt/ffmpeg/v345/ffmpeg-3.4.5$ ./ffmpeg -hwaccels
ffmpeg version 3.4.5 Copyright (c) 2000-2018 the FFmpeg developers
built with gcc 7 (Ubuntu 7.3.0-27ubuntu1~18.04)
configuration:
libavutil 55. 78.100 / 55. 78.100
libavcodec 57.107.100 / 57.107.100
libavformat 57. 83.100 / 57. 83.100
libavdevice 57. 10.100 / 57. 10.100
libavfilter 6.107.100 / 6.107.100
libswscale 4. 8.100 / 4. 8.100
libswresample 2. 9.100 / 2. 9.100
Hardware acceleration methods:
cuvid
-
Кажеться разобрался как разрулить с логами без перекомпиляции.
Поторопился. Без перекомпиляции кажеться нереально.
Там как я понял создаётся временный объект tensorflow/core/platform/default/logging.h
И по сути никаких логов там не ведётся.
-
4 минуты назад, Smorodov сказал:Перенаправить вывод в линуксе можно стандартно:
SomeCommand > SomeFile.txtПодробнее тут:https://askubuntu.com/questions/420981/how-do-i-save-terminal-output-to-a-fileДа эт я знаю, но программа может иметь свои сообщения. Хочеться не на уровне окружения(оболочки) решать вопрос.
есть класс SessionLog, причём как в питоне так и в плюсах. Ну не хочет пока выдавать лог.
-
8 минут назад, Smorodov сказал:Дык на чем остановились то ?
Не уверен что понял вопрос.
Щас пилю инференс. Там много вещей, которые нужны в любой задаче.
Особенно для меня загадка как аккуратно распределить GPU память между tensorflow, opencv, ffmpeg.
Предпологаеться что каждая либа будет использовать куду. Надо както расчитать сколько нужно памяти для модели.
Ну а прямо щас копаю как перенаправить логи, а то пишет много всего, но в терминал.
-
1 час назад, Smorodov сказал:Нашел тот старый проект TF_EX.RAR посмотрите, может пригодится.
Да всё, проблема с размерностью решена.

Щас осталось разобраться как контрлировать процесс с памятью для GPU и перенаправлений логов сессии в файл.
-
А вот так почти сработало, только понять бы в чём разница с предыдущем вариантом.
const auto size1 = 1; const auto size2 = 192; const auto size3 = 512; const auto size4 = 1; Tensor inputTensor1(DT_FLOAT, TensorShape({size1, size2, size3, size4})); //заполнение тензоров-входных данных for (int i1 = 0; i1 < size2; i1++) { for (int j1 = 0; j1 < size3; j1++) { inputTensor1.tensor<float, 4>()(0, i1, j1, 0) = 128.; } }
Теперь с GPU воевать придёться:
Цитата2019-09-14 22:24:12.077757: W tensorflow/core/common_runtime/bfc_allocator.cc:237] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.27GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
UPDATE:
В предыдущем сообщении была ошибка:
вместо
auto intensor = graph_def.node(1).attr().at("shape");
надо:
auto intensor = graph_def.node(1).attr().at("value");
-
3 часа назад, Smorodov сказал:Не уверен что хуже, задавать размер тензора вручную, или мешать C и C++, но так-то теоретически возможно:
https://www.oracle.com/technetwork/articles/servers-storage-dev/mixingcandcpluspluscode-305840.html
Может оптимально будет просто записывать при заморозке еще один файл, с дополнительной инфой ?
Пока забил вручную:
Но я не врублюсь какой размерности тензор создавать. В питоне было [-1, 192, 512, 1], а в плюсах
const auto size1 = 0; const auto size2 = 192; const auto size3 = 512; const auto size4 = 1; Tensor inputTensor1(DT_FLOAT, TensorShape({size1, size2, size3, size4}));
если создать с размерностью (0, 192, 512, 1) то при такой иннициаллизации:
for (int i1 = 0; i1 < size2; i1++) { for (int j1 = 0; j1 < size3; j1++) { inputTensor1.matrix<float>()(i1, j1) = 128; } }
я получаю ошибку времени выполнения :
Цитата2019-09-14 20:26:51.187250: F tensorflow/core/framework/tensor_shape.cc:44] Check failed: NDIMS == dims() (2 vs. 4)Asking for tensor of 2 dimensions from a tensor of 4 dimensions
А при такой иннициаллизации:
for (int i1 = 0; i1 < size2; i1++) { for (int j1 = 0; j1 < size3; j1++) { inputTensor1.matrix<float>()(0, i1, j1, 0) = 128; } }
такую на этапе компиляции:
Цитатаrequired from here
/usr/include/eigen3/unsupported/Eigen/CXX11/src/Tensor/TensorMap.h:239:7: error: static assertion failed: Number of indices used to access a tensor coefficient must be equal to the rank of the tensor.
static_assert(sizeof...(otherIndices) + 2 == NumIndices || NumIndices == Dynamic, "Number of indices used to access a tensor coefficient must be equal to the rank of the tensor.");
Вообщем очень сильно плаваю в ситуации, поэто и хотел задавать размерность на автомате чтоб меньше ошибаться.
UPDATE:
Я на самом деле вроде придумал как определять размерность и если я прав, то всё очень грустно, потомучто тензор в файле записан одномерным.
auto intensor = graph_def.node(1).attr().at("value"); Tensor tmp_tensor; bool result = tmp_tensor.FromProto(intensor); int num_dimensions = tmp_tensor.shape().dims(); std::cerr << num_dimensions << std::endl; for(int ii_dim = 0; ii_dim < num_dimensions; ii_dim++) { std::cerr << "i" << tmp_tensor.shape().dim_size(ii_dim) << std::endl; }
Потомучто я имею на любом узле num_dimensions равное единице.
-
В 9/12/2019 at 18:30, Smorodov сказал:Так там вроде как размеры тензоров при заморозке фиксируются, и надо самому их знать по модели. Вроде как получение размеров тензоров и не поддерживалось. Но тут у меня опыта немного, могу ошибаться.
А C API можно миксить с С++ API ?
Вот тут интересные рассуждения.
-
4 минуты назад, Smorodov сказал:Так там вроде как размеры тензоров при заморозке фиксируются, и надо самому их знать по модели. Вроде как получение размеров тензоров и не поддерживалось. Но тут у меня опыта немного, могу ошибаться.
Размер тензора вроде можно узнать, но мне надо конвертировать Node графа в тензор прежде и я без понятия как это сделать.
Да я конечно могу сам забить размер, но както дико ненадёжное реение получается от таких кастылей.
Второй вариант это всёже както сохранять аттрибуты в модели. Функция simple_save это както же делает.
В любом случае спасибо. Мне важно знать как делают другие.
-
Замарозку делал вот так:
def freeze_session(session, keep_var_names=None, output_names=None, clear_devices=True): """ Freezes the state of a session into a pruned computation graph. Creates a new computation graph where variable nodes are replaced by constants taking their current value in the session. The new graph will be pruned so subgraphs that are not necessary to compute the requested outputs are removed. @param session The TensorFlow session to be frozen. @param keep_var_names A list of variable names that should not be frozen, or None to freeze all the variables in the graph. @param output_names Names of the relevant graph outputs. @param clear_devices Remove the device directives from the graph for better portability. @return The frozen graph definition. """ graph = session.graph with graph.as_default(): freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or [])) output_names = output_names or [] output_names += [v.op.name for v in tf.global_variables()] # Graph -> GraphDef ProtoBuf input_graph_def = graph.as_graph_def() if clear_devices: for node in input_graph_def.node: node.device = "" frozen_graph = convert_variables_to_constants(session, input_graph_def, output_names, freeze_var_names) return frozen_graph frozen_graph = freeze_session(K.get_session(), output_names=[out.op.name for out in model.outputs]) tf.train.write_graph(frozen_graph, "model", "tf_model.pb", as_text=False)
-
Более подробно расписал в новой теме. -
Когда у меня была незамароженная модель я без труда определял размерность входного и выходного узла графа загруженной модели вот таким образом:
using namespace std; using namespace tensorflow; using namespace tensorflow::ops; cout << "Step1" << endl; GraphDef graph_def(true); Session* session; SessionOptions sopt; Status status = NewSession(sopt, &session); if (!status.ok()) { std::cerr << "tf error: " << status.ToString() << "\n"; } const string export_dir = "/home/user/MyBuild/build_tftest2/models"; SavedModelBundle bundle; RunOptions run_options; status = LoadSavedModel(sopt, run_options, export_dir, {kSavedModelTagServe}, &bundle); if (!status.ok()) { std::cerr << "tf error: " << status.ToString() << "\n"; } else { GraphDef graph = bundle.meta_graph_def.graph_def(); auto shape = graph.node().Get(0).attr().at("shape").shape(); for (int i = 0; i < shape.dim_size(); i++) { std::cout << shape.dim(i).size()<<std::endl; } int node_count = graph.node_size(); for (int i = 0; i < node_count; i++) { auto n = graph.node(i); //graph.node(i).PrintDebugString(); cout<<"Names : "<< n.name() <<endl; } }
А потом я захотел модель оптимизировать и для этого её заморозил и теперь код загрузки модели уже другой,
using namespace std; using namespace tensorflow; using namespace tensorflow::ops; cout << "Step1" << endl; GraphDef graph_def(true); Session* session; SessionOptions sopt; Status status = NewSession(sopt, &session); if (!status.ok()) { std::cerr << "tf error: " << status.ToString() << "\n"; } cout << "Step2" << endl; // Читаем граф //status = ReadBinaryProto(Env::Default(), "/home/user/MyBuild/build_tftest2/models/saved_model.pb", &graph_def); status = ReadBinaryProto(Env::Default(), "/home/user/MySoftware/foreign code/netology_JN/Diplom/Models/optimized/optim_model.pb", &graph_def); //status = ReadBinaryProto(Env::Default(), "/home/user/MySoftware/foreign code/netology_JN/Diplom/Models/Raw/frozen_model.pb", &graph_def); if (!status.ok()) { std::cerr << "tf error: " << status.ToString() << "\n"; } else { int node_count = graph_def.node_size(); for (int i = 0; i < node_count; i++) { auto n = graph_def.node(i); //graph.node(i).PrintDebugString(); cout<<"Names : "<< n.name() <<endl; } auto shape = graph_def.node().Get(0).attr().at("shape").shape(); for (int i = 0; i < shape.dim_size(); i++) { std::cout << shape.dim(0).size()<<std::endl; } }
Список узлов я по прежнему получаю, но при попытки получить размерность имею большой облом.
ЦитатаNames : conv2d_18_2/Relu
Names : conv2d_19_2/kernel
Names : conv2d_19_2/bias
Names : conv2d_19_2/convolution
Names : conv2d_19_2/BiasAdd
Names : conv2d_19_2/Sigmoid
[libprotobuf FATAL /usr/local/include/google/protobuf/map.h:1064] CHECK failed: it != end(): key not found: shape
terminate called after throwing an instance of 'google::protobuf::FatalException'
what(): CHECK failed: it != end(): key not found: shape
14:21:36: The program has unexpectedly finished.
Подскажите пожалуйста как получить размерность хотябы входного и выходного узла. Я же должен знать тензоры каких размерностей надо создавать для интеграции модели в приложение.
Документации по теме нет и я буду рад любым рассуждениям, которые могут навести на путь истинный.
-
В 9/8/2019 at 15:05, Smorodov сказал:Подкину еще один скрипт, выдранный из работающего проекта. FreezeMe.py тут некоторых вещей нехватает, но может чем и пригодится. И еще, чтобы смотреть что записалось попробуйте Netron, я его как то уже упоминал.
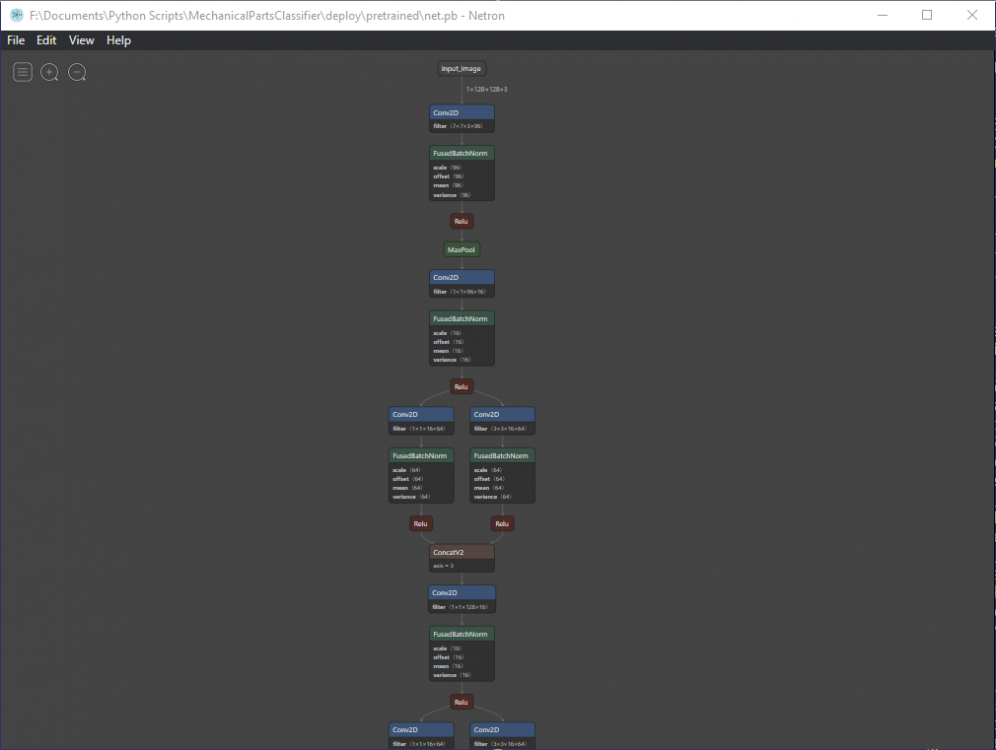
Спасибо, интересная утилита. Но у меня после всех оптимизаций кудато потерялись атрибуты и код:
GraphDef graph_def; ... auto shape = graph_def.node().Get(0).attr().at("shape").shape(); for (int i = 0; i < shape.dim_size(); i++) { std::cout << shape.dim(0).size()<<std::endl; }
приводит к исключению:
Цитата[libprotobuf FATAL /usr/local/include/google/protobuf/map.h:1064] CHECK failed: it != end(): key not found: shape
terminate called after throwing an instance of 'google::protobuf::FatalException'
what(): CHECK failed: it != end(): key not found: shape
22:06:41: The program has unexpectedly finished.
-
В 9/1/2019 at 11:06, Smorodov сказал:Скрипт заморозки модельки, на всякий случай. Keras2pb.py
Ага спасибо, только щас про него вспомнил. Он как раз с заморозкой.
-
Добрый день, подскажите пожалуйста как правильно "заморозить" модель tensorflow, сохранённую с помощью tf.saved_model.simple_save как ./out/saved_model.pb ?
#init_op = tf.initialize_all_variables() with tf.keras.backend.get_session() as sess: sess.run(init_op) tf.saved_model.simple_save( sess, export_path, inputs={'input': model.input}, outputs={'output': model.output}) saver.save(sess, 'tmp/my-weights')
Пробовал приспособить freeze_graph.freeze_graph, но безуспешно. Непонятно откуда брать outoute_node когда беру имя выходного узла из модели то в ответ читаю что данные узел не в графе.Щас вообще беда, даже чекпоинт не могу сохранить, который вроде нужен для замарозки:
def write_temporary(): init_op = tf.initialize_all_variables() export_path = './out' with tf.Session(graph=tf.Graph()) as sess: tf.saved_model.loader.load(sess, [tag_constants.SERVING], export_path) graph = tf.get_default_graph() tf.train.write_graph(graph, './outtmp', 'model_saved.pbtxt') #print([node.name for node in graph.as_graph_def().node]) #sess.run(init_op) with tf.Session(graph=tf.Graph()) as sess: tf.saved_model.loader.load(sess, [tag_constants.SERVING], export_path) graph = tf.get_default_graph() saver = tf.train.Saver([graph]) # #tf.train.write_graph(graph, './outtmp', 'model_saved.pbtxt') saver.save(sess, './outtmp/model.ckpt') #print([node.name for node in graph.as_graph_def().node]) sess.run(init_op) write_temporary()
-
17 часов назад, Nuzhny сказал:Я наверно упоротый параноик и из-за своей паранои проковырялся неделю. Я ж тоже когда сёрфил по инету наткнулся на эту репу https://github.com/FloopCZ/tensorflow_cc как и Вы Но тараканы в голове сказали что нельзя доверять неофициальной репе. Зато теперь я вооружён знаниями как собирать самому из первоисточника и не зависитеть от "добрых" людей.
-
Кажеться Победа, но я ещё пока не уверен.
Цитата2019-09-04 21:51:58.942504: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2019-09-04 21:51:58.953128: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcuda.so.1
2019-09-04 21:51:58.975675: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:58.976390: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: GeForce 940MX major: 5 minor: 0 memoryClockRate(GHz): 1.189
pciBusID: 0000:01:00.0
2019-09-04 21:51:58.976409: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check.
2019-09-04 21:51:58.976473: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:58.977287: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:58.977953: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2019-09-04 21:51:59.437425: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-09-04 21:51:59.437455: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0
2019-09-04 21:51:59.437461: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N
2019-09-04 21:51:59.437663: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:59.438447: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:59.439192: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-09-04 21:51:59.439826: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1286 MB memory) -> physical GPU (device: 0, name: GeForce 940MX, pci bus id: 0000:01:00.0, compute capability: 5.0)
-
10 минут назад, Nuzhny сказал:А точно, просто увидел твой текст про опции линковки и пропустил про рантайм.
Статья трёхлетней давности, кто его знает, правильно там или нет. Почему ты не собираешь стандартые примеры из репозитория TF? Зачем начинать с левой статьи?
Например ?
Оптимальное распараллеливание для CUDA для операции свёртки.
в Обсуждение общих вопросов
Опубликовано · Report reply
Добрый день, Хочу на простом примере распараллеливания операции свёртки понять как выбирать оптимальные значения для числа блоков, числа нитей и кошерно ли делать цикл внутри нити или надо максимально увеличить число блоков и нитей ?
Допустим матрица размером M*N
Допустим число ядер cuda, известное из документации.
Пока понял что для случая большой матрицы(изображения) лучше топить на число нитей в блоке так как всю её за раз не посчитаешь и планировщик нитей в варпе должен работать по идеи быстрей планировщика блоков, но кто быстрей внутренний цикл в ните или планировщик блоков ?
Когда матрица маленькая и может посчитаться за один цикл(распараллевание не больше чем число ядер), то я так понимаю надо наоборот число нитей надо брать в 1 варп(32), а число блоков надо брать число ядер/32.