
iskees
-
Количество публикаций
202 -
Зарегистрирован
-
Посещение
-
Days Won
19
Сообщения, опубликованные пользователем iskees
-
-
Вы caffe и DIGITS под виндой запустили?
-
А с чего Вы решили что это магитестрская диссертация, топик стартер писал же "диплом", а там нужна не научная новизна и прочее, а практическая ценность. Автор, укажите вы магистрант или бакалавр?
-
для примера, то чего не хватает для моих задач:
- Различные адаптивные бинаризации
- Все что связано с контурами, их поиск и фильтрация
- ASM, AAM
-
Может вам перевести на gpu что-то другое, чего еще никто не риализовал,, виола-джонс уже и так напихан в каждый "холодильник" и ничего нового вы не сделаете. Слабо себе переставляю диплом в котором переписывается то что давно реализованное(причем явно будет медленнее) и доказывается что на задаче со скользящим окном gpu быстрее cpu.
-
 1
1
-
-
Спасибо, теперь понятно как это работает. Возникла еще мысль, а что если использовать подобную сеть для распознавания лиц. На входе она получает фото лица, на выходе вектор. А примерами для обучения и настройки могут служить наборы лиц, если на одинаковые лица вектора близкие то положительно подкрепление если далекие то отрицательные, ну и на разные лица все наоборот.
-
Как я понял вы обсуждаете обычное скользящее окно в котором классификатор это нейронная сеть, а мне казалось что придумали какой-то метод использования сетей для сегментации изображения, а потом уже сегменты классифицируются(или одновременно как то). В демонстрации deepLab все выглядело именно так.
-
"Core i5 в обоих случаях составляет от 85-96%" что-то сильно много, у нас на full-hd 25fps с селеронами загрузка была на уроне 15%. Может у вас 85% это с учетом вывода изображения уже.
-
Вообще было бы интересно почитать про то как работают такие штуки (тот же deepLab ), может кто в теме статейку напишет.
-
Откуда форумчане могут знать что там у вас за данные идут с камеры, но раз у вас все таки ip камера и сомнительно что она чб то наверное стоит использовать CV_8UC3
-
Еще лучше работает комбинация двух методов:
1 О чем и была речь но с чуть "заниженным порогом"
2 Не помню как он называется, там можно взять все кадры из видео распознаваемого лица на них проводится "расчет" и полученному "распознавателю" предъявляются фотографии из базы прошедшие первый этап.
Ну и опыт показал что без приведение лиц к одному ракурсу и освещению все это вообще не работает(т.е. хотя бы мене 1% по обеим ошибкам)
-
У меня с 750ti подобная беда, правда у меня мать серверная и там вообще беда с pci-e. Винда работает без нареканий, а убунту те же ошибки но если так попробовать загружать раза 3-4 то система запускается и работает стабильно до перезагрузки. Ставил разные версии убунт, кубунт, драйвера, биос обновлял и никаких улучшений.
-
У большинства камер есть поддержка mjpeg, с ним как то проблем меньше да и проц без аппаратного декодирование не так грузит как h264.
-
1.Все описание есть на http://opencv.org/documentation.html на русском языке увы ничего нет, 2.4.11 это просто развитие ветки 2.0 добавили несколько функций и еще плотнее прикрутили gpu
2. Visual C++ 2013 и Visual C++ 2010 принципально ничем не отличается
-
Мне кажется, что люди и высшие животные строят карту глубины больше основываясь на знание эталонных размеров объектов в поле зрения нежели на стерео зрении. Пришел в голову эксперимент: снять два ролика, или просто статичный кадр
1 самая обычная обстановка, город или лес. Показываем на самом простом телевизоре.
2 компьютерная графика, в кадре только объекты в виде глянцевых кубов шаров и прочего так что бы вообще никаких ассоциация о размере не возникало. Показываем в 3Д.
Смотрящий в каждом ролике должен прикинуть расстояние до отмеченного объекта.
-
еще более влом линукс ставить ради этого

-
Emgu есть не для всех версий opencv. Много функцией есть не выведенных в Mat или Image, а существующих только в классе invwork, посмотрите может там есть нужная функция.
-
В Emgu начиная с третей версии Image<> заменен на Mat. Пример у вас от версии 2.Х, а используете вы 3.
-
Самописная для собственных нужд https://classifieropencv.codeplex.com/ "релиз" давно не обновлял, нужно качать код и компилировать.
-
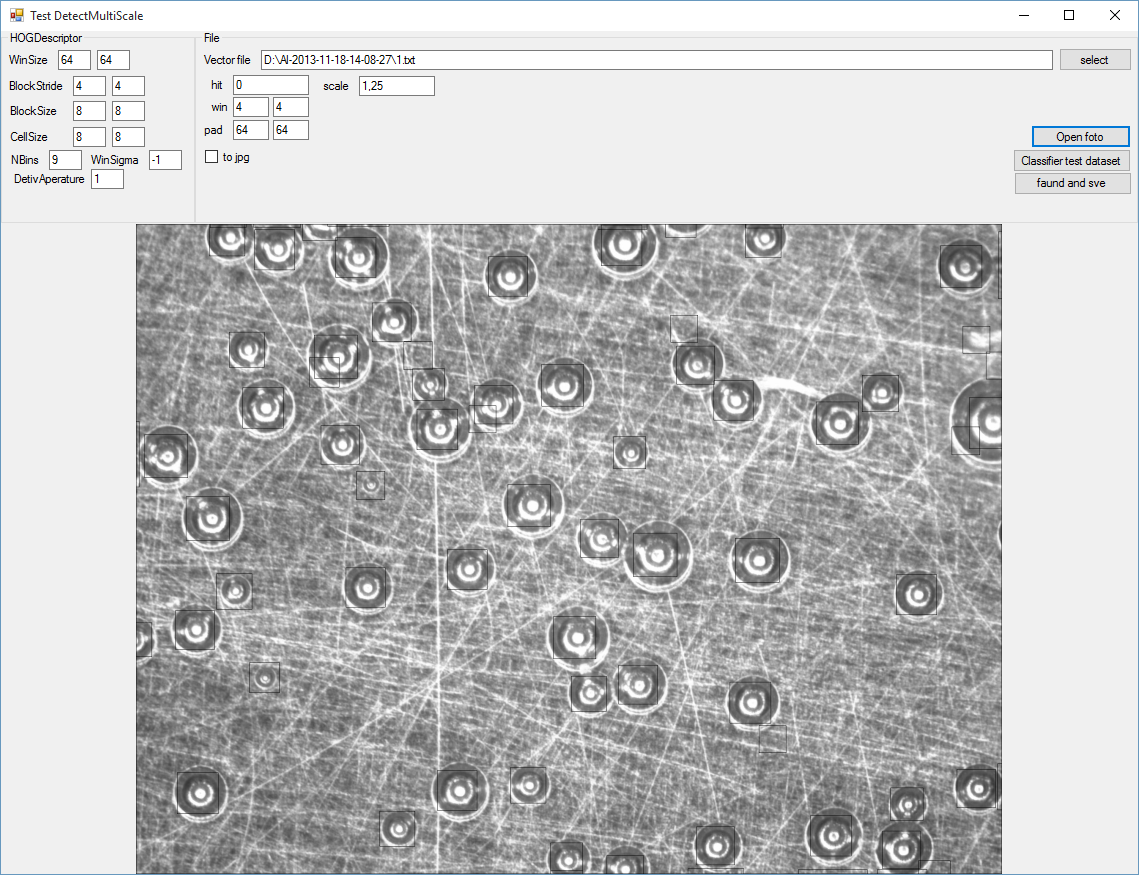
Попробовал hog-svm обучал "поверхностно" на двух фотографиях. Думаю если нормально обучить то результат будет вполне себе. Квадраты черные на сером, всматриваться нужно.
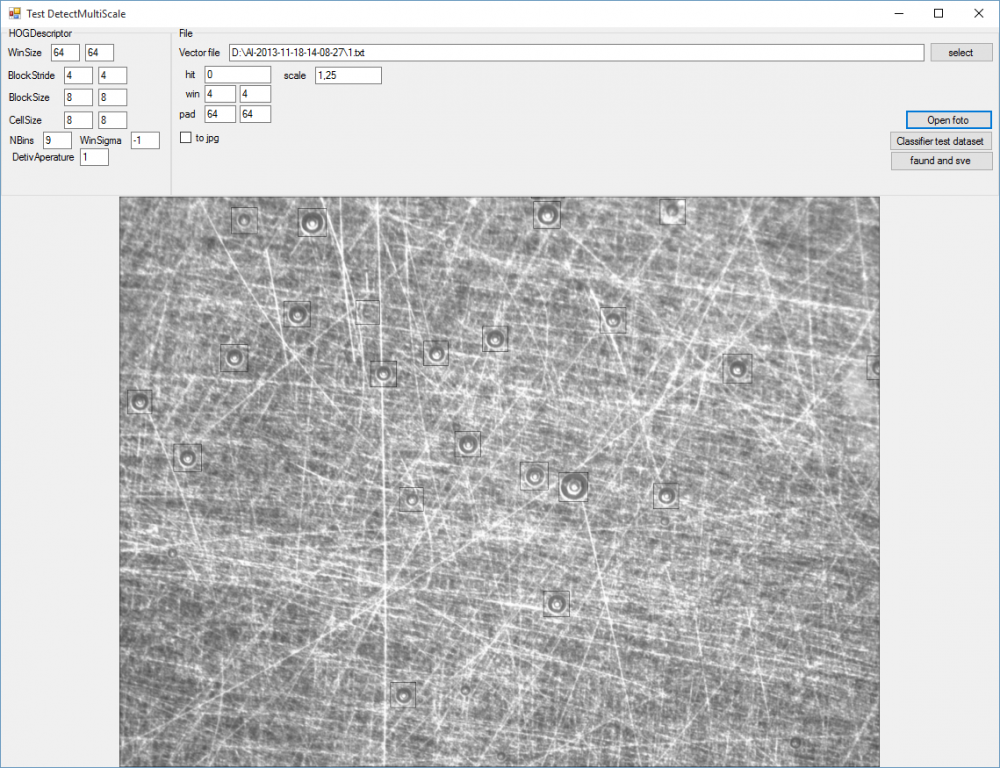
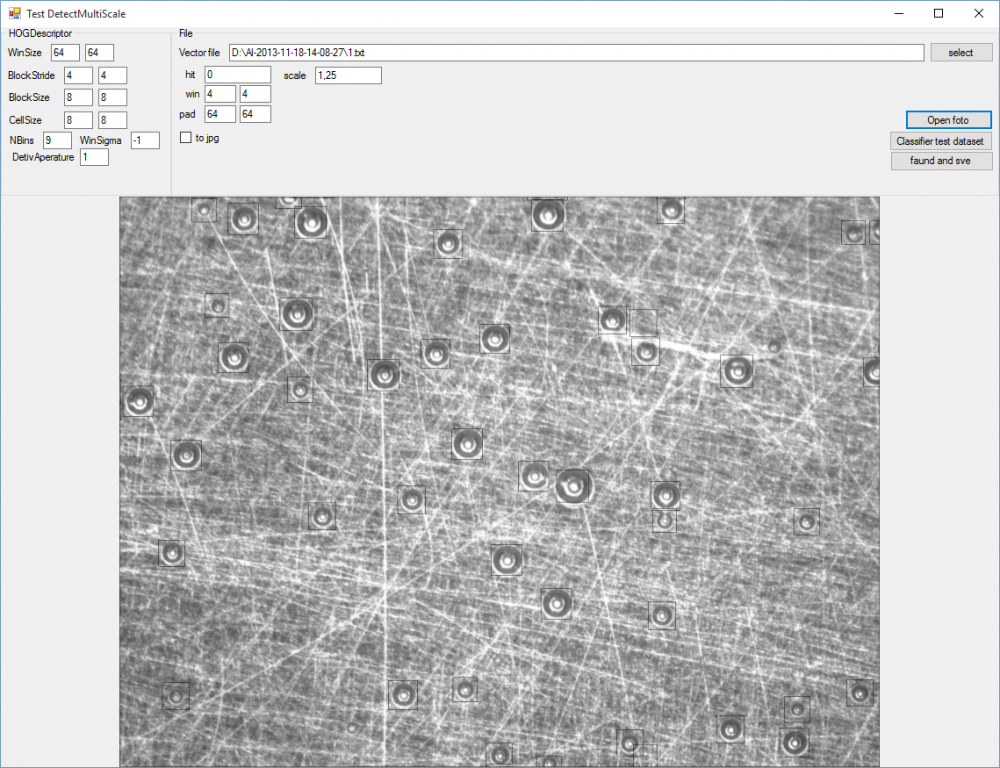
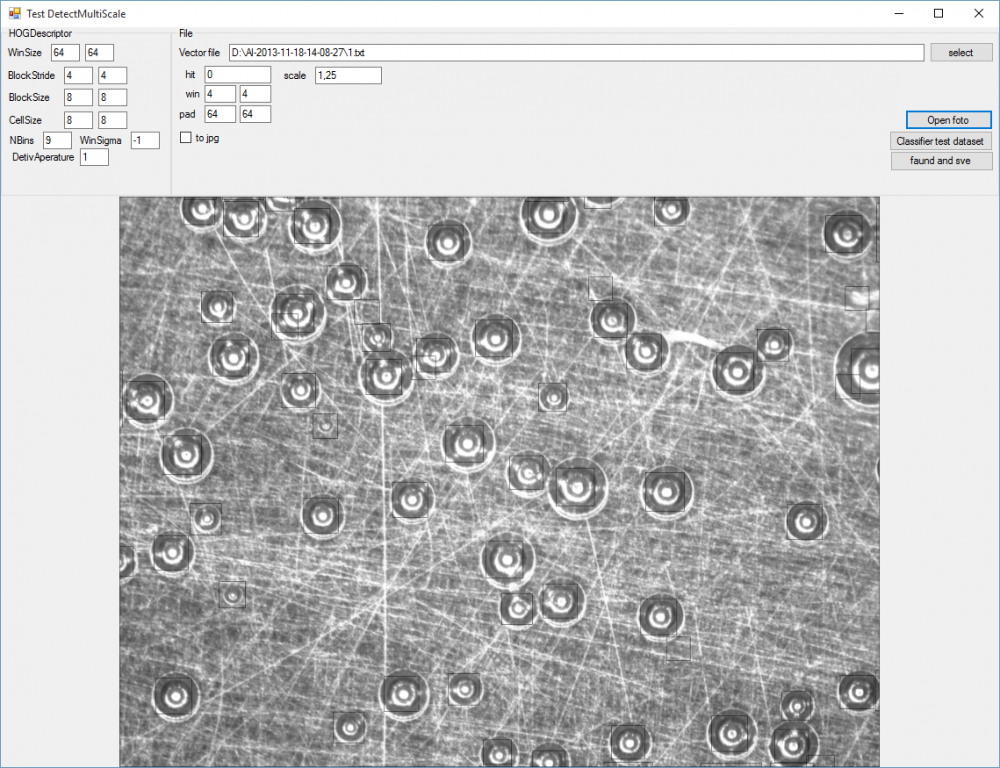
-
Да, оранжевый и светлый объект, темный и синий фон. По экспериментировать так что бы на выходе остались одни круги да полоски и хааф мог нормально найти окружности.
Хотя можно и детекторы попробовать, если есть 10ок таких изображение то можете скинуть я проверю веречром
-
Преобразование Хафа, и если уже делать бинарзацию то и по яркости и по цвету
-
Не понятно зачем вам именно работа со статичным кадром, но в таком случае ничего кроме детекторов типа svm-hog виоло-джонс сложно придумать.
Но если все же работать с видео то можно:
1 Детектор движения для выделения области движения, тут же можно отбросить всякую мелочь типа птиц на основе размеров
2 Классификатор , нейросеть там или еще что
3 Можно еще построить траекторию "машины", что бы фильтровать ложные сработки по их "телепортации"
-
кадр с видео выложите, а то гадание на кофейной гуще.
-
Как соберете сами это дело под винду, то выложите сюда. Тоже интересно посмотреть, но заниматься геморроем со сборкой и прочим нет желания.

CAFFE от MS
в Вопросы по нейросетям и ИИ
Опубликовано · Report reply
поделитесь ссылочный на инструкцию по которой делали