
mrgloom
-
Количество публикаций
2 302 -
Зарегистрирован
-
Посещение
-
Days Won
142
Сообщения, опубликованные пользователем mrgloom
-
-
Я смотрел эту репу и там как раз непонятно как всё делается так что не рекомендую.
Ибо загрузка из json, по мне так менее читаемо чем модель на питоне. А так там походу стандартный трюк с reshape+permute используется.
https://github.com/imlab-uiip/keras-segnet/blob/master/model_5l.json
Да и репа мертвая походу, на вопросы не отвечают
https://github.com/imlab-uiip/keras-segnet/issues/12
Как я понял в ф-ию которая считает crossentropy можно подавать матрицу и сумма по последнему дименшену должна быть 1.0 (т.е. после softmax), т.е. он посчитает по каждому row и проссумирует loss. Но всё это делается в неявном виде так что не очень приятно.
-
Возможно можно посчитать dice loss для каждого выхода - sigmoid'ы и проссумировать, чтобы получить общий loss, но не уверен.
А так в терминах keras'а можно использовать sigmoid + binary_crossentropy или softmax + categorical_crossentropy.
-
Проверил работает, но ограничение константная длина надписи.
Теперь интересно какой нибудь cnn+lstm накрутить как тут:
-
Похоже несколько аутпутов не надо, просто можно всё лепить в один вектор судя по этому проекту:
https://github.com/matthewearl/deep-anpr/blob/db823ebe283f4e226a80dbbe4cb5b45867bf0485/common.py#L39
https://github.com/matthewearl/deep-anpr/blob/db823ebe283f4e226a80dbbe4cb5b45867bf0485/train.py#L172
https://github.com/matthewearl/deep-anpr/blob/db823ebe283f4e226a80dbbe4cb5b45867bf0485/train.py#L125
http://matthewearl.github.io/2016/05/06/cnn-anpr/
Хотя в пейпере от гугла судя по картинке таки несколько аутпутов:
http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/42241.pdf
-
Модель
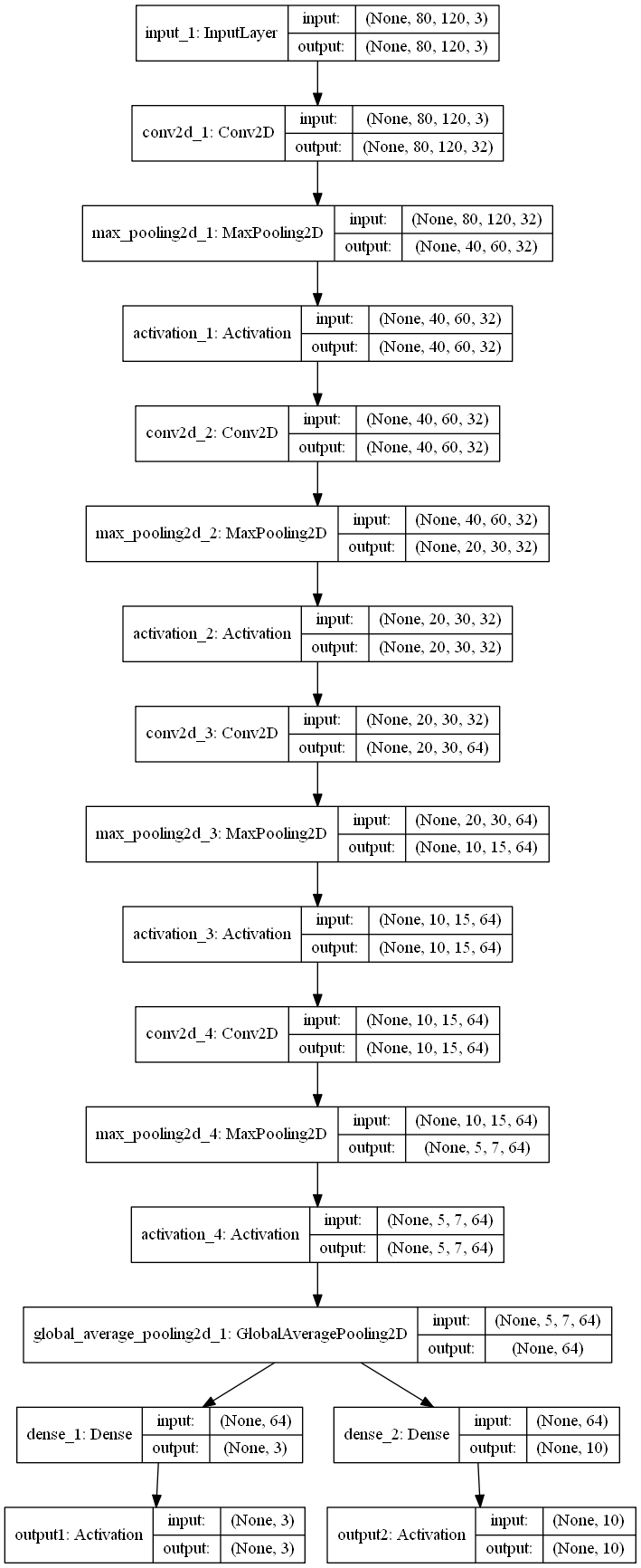
Сэмпл

Что то похожее делается тут на mxnet, но непонятно причем там конкат и какой там в итоге аутпут - матрица 10x4 ? как быть если у нас буквы и цифры, т.е. длины множеств разные (3 и 10 в изначальном примере)?
https://github.com/apache/incubator-mxnet/blob/master/example/captcha/mxnet_captcha.R#L13
и по сути изначальная синтетическая задача расширяется на номера машин и капчи.
Тоже самое тут только уже на python, а не на R и для plate recognition.
https://github.com/szad670401/end-to-end-for-chinese-plate-recognition/blob/master/train.py#L108
-
import cv2 import numpy as np import pandas as pd import keras from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Activation, Flatten, GlobalAveragePooling2D from keras.layers import Conv2D, MaxPooling2D from keras.layers import Input from keras.optimizers import SGD, RMSprop from keras.callbacks import ModelCheckpoint, EarlyStopping import sys #Two head - one for number and one for digit with constant positions #params list_a= ['0','1','2','3','4','5','6','7','8','9'] list_b= ['A','B','C'] dx= 20 dy= 50 font_scale= 1 batch_size= 32 epochs= 20 patience = 10 model_name= 'model.h5' input_dim= (80,120,3) def generate_random_plate_number(): img= np.zeros(input_dim, np.uint8) rand_indx_b= np.random.randint(len(list_b)) letter_str1= list_b[rand_indx_b] #print('letter_str',letter_str) # cv2.putText(img, letter_str1, (0,dy), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255,255,255), thickness=2) rand_indx_a= np.random.randint(len(list_a)) number_str1= list_a[rand_indx_a] #print('number_str',number_str) # cv2.putText(img, number_str1, (2*dx,dy), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255,255,255), thickness=2) y1= np.zeros((len(list_b)), np.int32) y2= np.zeros((len(list_a)), np.int32) y1[list_b.index(letter_str1)]= 1 y2[list_a.index(number_str1)]= 1 #print('y1', y1) # #print('y2', y2) # return img,y1,y2 def batch_generator(batch_size): while True: image_list = [] y1_list = [] y2_list = [] for i in range(batch_size): img,y1,y2= generate_random_plate_number() image_list.append(img) y1_list.append(y1) y2_list.append(y2) image_arr = np.array(image_list, dtype=np.float32) y1_arr = np.array(y1_list, dtype=np.int32) y2_arr = np.array(y2_list, dtype=np.int32) #print('image_arr.shape', image_arr.shape) # #print('y1_arr.shape', y1_arr.shape) # #print('y2_arr.shape', y2_arr.shape) # yield(image_arr, {'output1': y1_arr, 'output2': y2_arr} ) def get_model(): network_input = Input(shape=input_dim) conv1= Conv2D(32, (3, 3), padding='same')(network_input) pool1= MaxPooling2D(pool_size=(2, 2))(conv1) act1= Activation('relu')(pool1) conv2= Conv2D(32, (3, 3), padding='same')(act1) pool2= MaxPooling2D(pool_size=(2, 2))(conv2) act2= Activation('relu')(pool2) conv3= Conv2D(64, (3, 3), padding='same')(act2) pool3= MaxPooling2D(pool_size=(2, 2))(conv3) act3= Activation('relu')(pool3) conv4= Conv2D(64, (3, 3), padding='same')(act3) pool4= MaxPooling2D(pool_size=(2, 2))(conv4) act4= Activation('relu')(pool4) tail= GlobalAveragePooling2D()(act4) #global_pool= GlobalAveragePooling2D()(act4) #tail= Dense(128)(global_pool) #add heads head1= Dense(len(list_b))(tail) softmax1= Activation('softmax', name='output1')(head1) head2= Dense(len(list_a))(tail) softmax2= Activation('softmax', name='output2')(head2) model = Model(input = network_input, output = [softmax1,softmax2]) model.compile(optimizer = RMSprop(1e-3), loss = {'output1': 'categorical_crossentropy', 'output2': 'categorical_crossentropy'}) #print(model.summary()) # #sys.exit() # return model def train(): model= get_model() callbacks = [ EarlyStopping(monitor='val_loss', patience=patience, verbose=0), ModelCheckpoint('model_temp.h5', monitor='val_loss', save_best_only=True, verbose=0), ] history = model.fit_generator( generator=batch_generator(batch_size), nb_epoch=epochs, samples_per_epoch=1*batch_size, validation_data=batch_generator(batch_size), nb_val_samples=1*batch_size, verbose=2, callbacks=callbacks) model.save_weights(model_name) pd.DataFrame(history.history).to_csv('train_history.csv', index=False)
Задача (не реальная) на картинке (80,120,3) в константных местах стоят(разные) цифра и буква, соответственно создаем общее 'тело' и 2 'головы'(для буквы и цифры), но чего то так не учится. Есть какие то соображения или типа задача weakly supervised и её сложно\невозможно в такой постановке решить?
-
Тут именно genetic programming упоминается
https://github.com/rhiever/tpot
Но tpot это опять же к вопросу оптимальных параметров моделей(хотя там еще какие то типо ансамбли из моделей вроде) из sklearn, а не ваш таск.
-
Просто grid search с отстреливанием по времени исполнения\пику памяти не подходит?
Есть еще варианты с bayesian optimization и genetic programming, но я это встречал скорее в контексте подбора параметров модели для ML.
Есть вообще то что то почитать на предмет оптимизаторов которые работаю по сути с черным ящиком(без градиента и т.д.)?
-
По opencv dnn написано ' поддержка основных слоев нейронных сетей ', т.е. как и все прочие 'конвертеры' тут как я предполагаю есть много но.
-
В Photoscan кстати есть генерация DEM / Orthophoto from Dense cloud, не знаю как по поводу качества, но по памяти это должно быть экономнее чем из меша.
-
В Caffe LSTM layer есть, но я не пробовал:
http://caffe.berkeleyvision.org/tutorial/layers/lstm.html
На caffe я бы не ставил.
MXNet я не пробовал, но это выглядит более подходящим вариантом, и как бонус там еще есть поддержка Mobile Devices и Distributed Training.
Есть еще такой проект, но видимо LSTM/RNN там в зачаточном состоянии.
https://github.com/tiny-dnn/tiny-dnn
Вообще меня тоже интересует вопрос как например python код из Keras перевести на C++, по идее можно Keras->Tensorflow->Tensorflow C++ (но возможно C++ api не полный?) ?
-
-
Итак небольшой апдейт
OpenMVS может сделать orthophoto и у вас не получается потому что не правильно выставлена нормаль, но как её найти это вопрос, возможно можно попробовать нормаль к геоиду? или нормаль к 'поверхности земли'. В целом же проект OpenMVS вроде как не про это.
https://github.com/cdcseacave/openMVS/issues/232
OpenMVG - возможно скоро появится такая функциональность.
https://github.com/openMVG/openMVG/issues/914
https://github.com/openMVG/openMVG/issues/978
Есть еще такое - идея нашлепать изображения в мозаику используя матрицу гомографии, не знаю насколько это только получится orthophoto.
https://github.com/openMVG/openMVG/issues/447
OpenDroneMap - судя по описанию как раз всё что нужно умеет, но я не пробовал, хочу попробовать под VM или docker. Использует внутри другой SFM 'движок' не OpenMVG.
-
Можете описать весь pipeline что вы делаете? а то я OpenMVG/OpenMVS не пользовался.
Большие числа это похоже на ECEF, а не GPS.
По идее всё же можно сначала решить задачу генерации ортофотоплана (вид сверху), а потом через gdal варпнуть и загеореференсить (но надо еще как то получить матрицу афинного преобразование gps to pixel).
-
Не помню точно, геореференсед ли этот tiff, но судя по проекции (которая кстати выглядит не как вид сверху ), не знаю как она называется Geographic ?
может Model Tie Point это то?
exiftool raw output:
ExifTool Version Number : 10.59
File Name : ortho.tif
Directory : .
File Size : 32 MB
File Modification Date/Time : 2016:07:31 20:27:32+03:00
File Access Date/Time : 2016:07:31 20:27:30+03:00
File Creation Date/Time : 2016:07:31 20:27:10+03:00
File Permissions : rw-rw-rw-
File Type : TIFF
File Type Extension : tif
MIME Type : image/tiff
Exif Byte Order : Little-endian (Intel, II)
Image Width : 3694
Image Height : 4096
Bits Per Sample : 8 8 8 8
Compression : LZW
Photometric Interpretation : RGB
Strip Offsets : (Binary data 1085 bytes, use -b option to extract)
Orientation : Horizontal (normal)
Samples Per Pixel : 4
Rows Per Strip : 32
Strip Byte Counts : (Binary data 875 bytes, use -b option to extract)
Planar Configuration : Chunky
Extra Samples : Unassociated Alpha
Sample Format : Unsigned; Unsigned; Unsigned; Unsigned
Pixel Scale : 1.86495400739727e-006 1.4079864172345e-006 0
Model Tie Point : 0 0 0 -81.7080861843233 41.2293646671544 0
Geo Tiff Version : 1.1.0
GT Model Type : Geographic
GT Raster Type : Pixel Is Area
Geographic Type : WGS 84
Geog Citation : WGS 84
Image Size : 3694x4096
Megapixels : 15.1Думаю более точно можно посмотреть через gdalinfo, там должна быть информация Corner Coordinates и Origin
http://www.gdal.org/gdalinfo.html
Да, что то не то, возможно я когда то ресайзил его и тэги дропнулись.
gdalinfo ortho.tif
Driver: GTiff/GeoTIFF
Files: ortho.tif
Size is 689, 576
Coordinate System is `'
Metadata:
TIFFTAG_DOCUMENTNAME=/tmp/ortho.tif
TIFFTAG_SOFTWARE=GraphicsMagick 1.3.18 2013-03-10 Q8 http://www.GraphicsMagick.org/
Image Structure Metadata:
COMPRESSION=LZW
INTERLEAVE=PIXEL
Corner Coordinates:
Upper Left ( 0.0, 0.0)
Lower Left ( 0.0, 576.0)
Upper Right ( 689.0, 0.0)
Lower Right ( 689.0, 576.0)
Center ( 344.5, 288.0)
Band 1 Block=689x2 Type=Byte, ColorInterp=Red
Mask Flags: PER_DATASET ALPHA
Band 2 Block=689x2 Type=Byte, ColorInterp=Green
Mask Flags: PER_DATASET ALPHA
Band 3 Block=689x2 Type=Byte, ColorInterp=Blue
Mask Flags: PER_DATASET ALPHA
Band 4 Block=689x2 Type=Byte, ColorInterp=AlphaМеня кстати больше интересует генерация geotiff из point cloud. И еще раз geotiff != orthomap?
-
А к GPS как привязано? каждый узел сетки? или общий bbox?
Меня тоже интересует этот вопрос, по идее достаточно только gps bbox + высоты точки (altitude) чтобы получить pixel to gps.
gdal не работает с point cloud или mesh, для привязки растра к GPS координатам можно использовать Affine GeoTransform
http://www.gdal.org/gdal_datamodel.html
В итоге orthomap выглядит как то так:
https://habrastorage.org/web/629/0e3/521/6290e352148b43f384513357847c26db.tif
Фотки отсюда, можно на этом поэксперементировать.
-
8 часов назад, prim.ko сказал:Как выглядит реализация этого решения? Это будет как на imagenet`e?
Не понял что вы имеете ввиду, на вход подаются пары похожие пары тайлов и не похожие пары тайлов, после обучения сеть отвечает на вопрос похожи ли 2 конкретных тайла или нет, есть еще tripple loss где подаются тройки, но идея примерна такая же.
В репе Keras'a есть пример, наверно можно улучшить заменив MLP на CNN.
https://github.com/fchollet/keras/blob/master/examples/mnist_siamese_graph.py
-
 1
1
-
-
1. KCF сейчас топ трекер?
2. Если такие датасеты в публичном доступе как в пейпере social lstm?
-
Как насчёт того чтобы натренировать siamese network для определения меры похожести тайлов?
-
-
А из чего это следует |log2(max(max(H,W), 256)/256|+1 ?
Похоже что в таком идеальном случае можно сравнивать через template matching или chamfer matching.
На кагле кстати была задача по сегментации спутниковых фотоснимков https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection
p.s. задача интересная, держите нас в курсе.
-
Сначала надо поставить английскую версию Visual Studio чтобы было легче гуглить ошибки и другим программистам понимать их смысл.
-
https://deepsystems.ai/works/deeplearning/airport-defects-detection
Есть идеи как можно решить данную задачу с помощью CNN etc.
Есть работы связанные с edge, но это вроде не совсем то.
-
не гонял, но есть еще такое (но там без эмоций, но можно расширить самому)
Измеритель пульса по изображению участка кожи.
в OpenCV
Опубликовано · Report reply
Изначально decision tree, т.к. этот метод интерпретируемый, т.е. там дерево из threshold'ов которые выучены из данных, чтобы не было таких вот хардкодов threshold'ов или in range как тут:
http://bytefish.de/blog/opencv/skin_color_thresholding/
https://github.com/WillBrennan/SkinDetector
И да их сначала можно выучить, а потом для скорости захардкодить)
Такой же вопрос почему в grabcut используется GMM? по сути нам там без разницы какой метод будет выдавать probability пикселя?
https://github.com/opencv/opencv/blob/c8783f3e235f81edb97279fafabcf12ec43ccc9f/modules/imgproc/src/grabcut.cpp