
mrgloom
-
Количество публикаций
2 302 -
Зарегистрирован
-
Посещение
-
Days Won
142
Сообщения, опубликованные пользователем mrgloom
-
-
openMVG + openMVS эта связка умеет тоже самое что умеет Photoscan, т.е. создание orthophoto, DEM, экспорт параметров камер?
-
Тренируйтесь пока на LFW.
В OpenFace нет построения индекса? в том же OpenBR есть, но не знаю какой точно алгоритм, скорее даже правильно будет сказать пайплайн.
Еще у них есть не только L2 http://openbiometrics.org/docs/plugin_docs/distance/
-
L2 norm =1, т.е. они нормированы.
-
При добавлении в базу персон на постоянной основе вам придется переучивать классификатор (который поверх 128d фич), а поиск ближайшего в базе не страдает этим недостатком.
-
Кстати по поводу t-sne:
Я пробовал t-sne на дефолтах и получилось не лучше pca, а если надо подбирать параметры то реально ли картинка будет показывать насколько фичи различимы, ведь существует множество наборов параметров, а значит множество возможных проекций, некоторые из которых хуже, некоторые лучше.
Для pca маппинг идеально разделимых класов это 'ромашка'?
https://github.com/mrgloom/Kaggle-Two-Sigma-Connect-Rental-Listing-Inquiries-Feature-Visualization
Могу попробовать тоже самое на VGGFace, но непонятно какие кропы ему необходимо подавать - т.е. хотелось бы увидеть пример обучающей выборки.
-
Можно просто поиск ближайшего соседа в базе
Можно классификацию на N заданных персон.
-
ЦитатаБеда моя в том, что без достоверности (вероятности),в любом виде, ничего у меня не выйдет, т.к. у меня нет четких областей в которых я распознаю символ. а есть набор предположительно областей, каждую из которых я отправляю на распознавание и вот по достоверности( вероятности) хотел определять, что-же за символ на самом деле передо мной.
Может решить бинарную задачу символ-не символ? если я правильно понял у вас что то типа скользящего окна по изображению на котором есть символы и фон и вы хотите по порогу определить где фон.
Можно CNN
На С++: Caffe+DIGITS можно легко обучить, деплой чуть сложнее.
На python полегче:
Если хотите sliding window можете присмотреться к этому примеру, который будет быстрее чем naive sliding window.
https://github.com/mrgloom/Fully-Convolutional-Example/blob/master/fully_convolutional_example.ipynb
-
Регрессия вроде именно регрессия, но применять её к задаче классификации не адекватно, т.к. у вас 'расстояние' между 1 и 2 будет меньше чем между 1 и 10, а в задаче классификации 'расстояние' должно быть одинаковым.
По вероятности есть такой вот раздел в LibSVM:
http://www.csie.ntu.edu.tw/~cjlin/papers/libsvm.pdf
8 Probability Estimates (page 30)
SVM predicts only class label (target value for regression) without probability information.
Можно вот такой хак (прочитайте коменты):
https://stackoverflow.com/a/27739386/1179925
P.s. простым языком объяснить можно почему confidence score!=probability?
От себя добавлю:
Я пробовал решать https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition#evaluation
там предполагается что вы предсказываете вероятность собаки для картинки в интервале [0,1]
Я использовал Linear SVM поверх CNN фич и результат был не очень(т.е. хуже чем просто ответы CNN затрейненой с
Softmax), видимо потому, что пробабилити из SVM было не 'затюнено'?Вот еще некоторые ссылки по теме:
UPDATE:
If
trueand the problem is 2-class classification then the method returns the decision function value that is signed distance to the margin, else the function returns a class label (classification) or estimated function value (regression).Прочитал еще раз и понял что distance to hyperplane возвращается только в случае бинарной классификации, т.е. когда например 10 цифр то возращается по тихому лейбл.
Вот и код
-
-
Source
imageis modified by this function. Also, the function does not take into account 1-pixel border of the image (it’s filled with 0’s and used for neighbor analysis in the algorithm), therefore the contours touching the image border will be clippedтак что
findContours(gray.clone(), contours, CV_RETR_LIST, CV_CHAIN_APPROX_NONE, cv::Point(0, 0));
-
 1
1
-
-
А одно и тоже значение какое выдаёт? может какой то 'краевой' случай?
Есть такой пример, правда он на питоне, но хотя бы можно параметры SVM оттуда взять
http://docs.opencv.org/trunk/dd/d3b/tutorial_py_svm_opencv.html
-
И это опять же не probability, а distance to hyperplane.
-
Для задачи классификации он возвращает label
http://docs.opencv.org/2.4/modules/ml/doc/support_vector_machines.html#cvsvm-predict
-
Что может означать такой график?
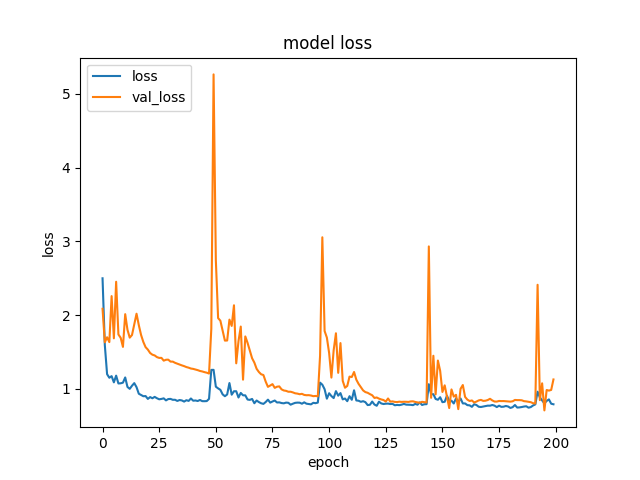
-
есть всякие там text detection in the wild
http://www.robots.ox.ac.uk/~vgg/research/text/
ну или stroke width transform
-
Я делаю в keras через callback'и
Цитатаearly_stopping_callback = EarlyStopping(monitor='val_loss', patience=epochs_to_wait_for_improve)
checkpoint_callback = ModelCheckpoint(model_name+'.h5', monitor='val_loss', verbose=1, save_best_only=True, mode='min')
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size),
steps_per_epoch=len(X_train) / batch_size, validation_data=(X_test, y_test),
epochs=n_epochs, callbacks=[early_stopping_callback, checkpoint_callback])
#Plot will be only for n_epochs, where loss will be averaged for steps_per_epoch batches
fig = plt.figure()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
fig.savefig(model_name+'_graph.png', dpi=fig.dpi)Точки на графике это уже усредненное по батчам, т.е. среднее на эпоху.
Попробовал просто увеличить кол-во эпох которые ждать и скорее всего это уже overfit, опять же из-за 'критов'.
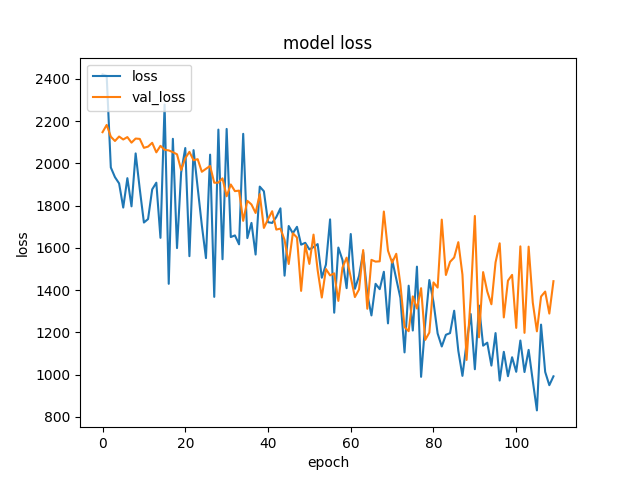
-
Т.е. скорее даже вопрос как сделать val_loss более гладким - просто больше batch_size и меньше learning rate?
Например вот график, где я использую early stopping и хотя тенденция к уменьшению val_loss есть, но из-за 'крита' (примерно на эпохе 50) обучение останавливается.
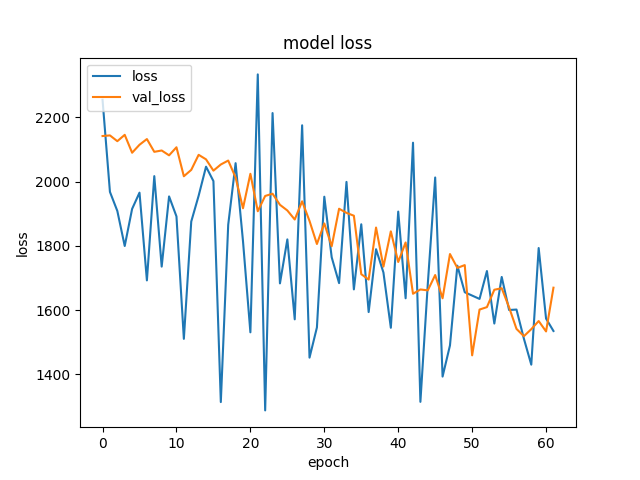
-
Предлагаю в этой теме по графику loss и val_loss делать те или иные предположения.
Например почему к концу графика разброс val_loss становится больше?
https://habrastorage.org/web/7af/80e/22c/7af80e22c81447099cf43ea80f9b6ace.png
-
Насколько я помню когда я ковырял dlib там не было примера как обучить несколько HOG детекторов под разными углами(т.е. только 1), но сам обученный классификатор для лиц имел как раз несколько темплейтов с разным поворотом.
И у меня это плохо работало на объектах которые повернуты когда был натренирован 1 HOG детектор.
Насчет CNN для классификации обычно делают horizontal flip, т.е. это норм, но это не тоже самое, когда объект крутится на 360 градусов, хотя на kaggle решали задачи с планктоном и галактиками где вроде те же проблемы.
-
1) Не смог этого быстро понять по коду, попробуйте вынести stitching_detailed.cpp в отдельный файл и добавляйте код постепенно(или только то что нужно) и смотрите на входные данные, это позволит понять на что влияет каждый шаг пайплайна.
2) Скорее всего это просто не в координатах изображения, а все изображения варпятся на некоторую координатную сетку.
3) Находит минимальный разрез на графе, пиксели это вершины графа, edges можно задавать просто как разницу между изображениями, но может это делается как то более умно
например
http://www.maths.lth.se/matematiklth/personal/petter/rapporter/panorama2.pdf
-
focal это видимо focal length параметр камеры
http://docs.opencv.org/2.4/doc/tutorials/calib3d/camera_calibration/camera_calibration.html
Можете еще почитать Computer Vision: Algorithms and Applications Richard Szeliski раздел Image stitching
-
1
-
-
1. Bundle Andjustment это глобальная оптимизация параметров камер, там видимо 2 разных метода.
2. Считается медиана focal length от всех камер?
3. Морфологическая операция на бинарной маске http://docs.opencv.org/2.4/doc/tutorials/imgproc/erosion_dilatation/erosion_dilatation.html
4.
[По Multiband blending paper: BA83] Burt, P., and Adelson, E. H., A Multiresolution Spline with Application to Image Mosaics. ACM Transactions on Graphics, 2(4):217-236, 1983. -
1
-
-
В keras вот такая штука есть https://keras.io/io_utils/
По идее можно написать свой batch_generator поверх lmdb, leveldb, hdf5 который читается последовательно, но содержит shuffled data.
-
1. По поводу похожести можно bag-of-words на базе sift
https://github.com/shackenberg/Minimal-Bag-of-Visual-Words-Image-Classifier
2. Всякие перцептвные хеши
3. Ну и фичи из CNN сетей для CBIR (хотя сейчас даже дескрипторы типа sift делаются через нейросети)
На счёт этого ' после чего восстановить второе на сколько это возможно близко к первому ' скорее всего только 1 подход поможет, т.к. там можно заматчить точки и получить матрицу гомографии.
{kind=link}
stereo_calib и stereo_match
в OpenCV
Опубликовано · Report reply
1. Правильно ли я понимаю, подразумевается что примеры stereo_calib и stereo_match должны использоваться для 2-х камер которые закреплены между собой 'палкой' и не обязательно чтобы линия на которой они находятся была параллельна 'полу'?
2. Возможно ли из простых камер подключенных по USB сделать стереокамеру? т.е. насколько я понимаю нужно чтобы кадры с камер брались синхронизировано.