
mrgloom
-
Количество публикаций
2 302 -
Зарегистрирован
-
Посещение
-
Days Won
142
Сообщения, опубликованные пользователем mrgloom
-
-
Люди это pedestrian detector? Думаю работать будет, но не факт, что это лучший выбор.
По pedestrian detector, вот это посмотрите
-
-
Вы имели ввиду FAST? https://www.edwardrosten.com/work/fast.html
Если правильно понял, то вот
https://github.com/nenadmarkus/pico
https://github.com/biotrump/NPD
-
-
Можно попробовать представить эти свойства в виде float вектора и решать задачу N мерной регрессии.
И соответственно data augmentation можно делать имея модель этих преобразований.
-
batch accumulation называется, на самом деле это есть и в обычном Caffe, называется iter_size и прописывать надо в solver.prototxt
https://github.com/BVLC/caffe/pull/1977
-
Тут https://github.com/BVLC/caffe/issues/401 пишут что
1. это может быть драйвер - с каким вы используете gtx 1070?
2. это может быть random initialization - но это вроде пофиксили.
3. это может быть weight initialization - попробую инициализировать bias константой поменьше.
тут https://github.com/BVLC/caffe/issues/3243
рекомендуют другие более продвинутые инициализации весов и batch norm
тут https://github.com/BVLC/caffe/issues/2731 рекомендуют уменьшить learning rate
Еще про уменьшение batch size при нехватке памяти
https://github.com/BVLC/caffe/issues/430
ЦитатаIn theory when you reduce the batch_size by a factor of X then you should increase the base_lr by a factor of sqrt(X), but Alex have used a factor of X (see http://arxiv.org/abs/1404.5997)
-
Отвечая на свой вопрос, проверил на AlexNet.
Можно вычитать среднее изображение или пиксель (разница между подходами на деле минимальна), но с вычитанием явно быстрее сходится, насчёт максимальной достижимой accuracy не проверял.
Еще из AlexNet можно спокойно убрать LRN слои.
-
У меня было такое, что 5-10 эпох сеть не подаёт признаков жизни, а потом начинает учится или даже более экзотично не учится потом небольшой всплеск в положительную сторону и потом опять возвращается к исходному состоянию.
Как понять что хотя бы какие то положительные тендеции происходят если loss не меняется как то анализировать состояние слоёв?
В случае с VGG увеличения batch size помогло.
У меня как раз 1070, а caffe вроде master 0.15 https://github.com/NVIDIA/caffe
AlexNet учится стабильно.
Единственный удачный запуск SqeezeNet v1.1, который правда закончился ошибкой
-
Так вы хотите детектирование маркеров и потом расположить картинки на заранее известном расстоянии для сшивки в панораму?
Попробовал 2 соседние картинки сложить руками через FIJI-%3EPlugins-%3EStitching-%3EMosaicJ

Автоматически не пробовал склеивать, но перекрытие слишком маленькое и много повторяющихся структур так что думаю будет много ошибок.
Так же можете попробовать для склейки Grid панорамы
http://research.microsoft.com/en-us/um/redmond/projects/ice/
А так для микроскопии можете это посмотреть https://www.fei.com/software/ , а точнее это https://www.fei.com/software/maps/
-
Что делать если Loss не уменьшается? как лечить? как дебажить?
Пока пробовал только увеличение batch size и не помогло.
Сетка Network In Network, хотя таким страдает и SqeezeNet v1.1 (только 2 раза получилось обучить с положительным результатом и даже не получается повторить результаты на том что работало)
-
Это вообще панорама? Если да, то укажите номера изображений в виде матрицы как они расположены.
-
Не написано какого размера изображение, неплохо было бы вывести график зависимости времени от размера изображения.
Тут не используется многопоточность на CPU, только если внутри самого resize, тоже и для GPU по идее можно кидать данные батчами.
Еще когда будете использовать многопоточный код важно померить именно wallclock time.
boost::timer::cpu_timer timer; ... boost::timer::cpu_times elapsed = timer.elapsed(); cout << "Processing : "<< " WALLCLOCK TIME: " << elapsed.wall / 1e9 << " seconds" << endl;
-
Всё правильно.
Если FANN поддерживает только MLP, то результат будет заведомо хуже, см. для сравнения секции Neural Nets и Convolutional nets.
-
Провёл еще такой простой эксперимент данные из соревнования Cats vs Dogs https://www.kaggle.com/c/dogs-vs-cats
Загнал это всё в DIGITS и сделал базы с размерами 256x256, 128x128, 64x64, 32x32
Попробовал загнать эти базы в сетки Lenet, AlexNet.
Так вот сеть данные то кушает в большинстве случаев, т.к. меняется только одна из размерностей первого слоя(?) при изменении размеров входного блоба, но само обучение не идет и соответственно вопрос как при сохранении архитектуры сети поменять размерности слоев так чтобы сеть подстроилась под размер изображения? Возможно ли это делать автоматически?
Попозже если надо могу выложить графики\логи.
-
Я сжал до стандартного размера для Lenet 28x28 методом squeeze (просто рейсайз?)
по MNIST и Lenet
https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md
про finetuning
https://github.com/NVIDIA/DIGITS/tree/master/examples/fine-tuning
Если у вас нет проблем с linux, то можно накатить на ubuntu 14.04 DIGITS+Caffe без проблем. Хотя и на винду должно ставиться(нужен VS2013 для сборки Caffe).
https://github.com/NVIDIA/DIGITS/blob/master/docs/BuildDigitsWindows.md
Но после обучения модели надо еще быть готовым к тому чтобы прикрутить Caffe к своему проекту и написать inference на C++ с выводом например в текстовый файл или куда еще.
-
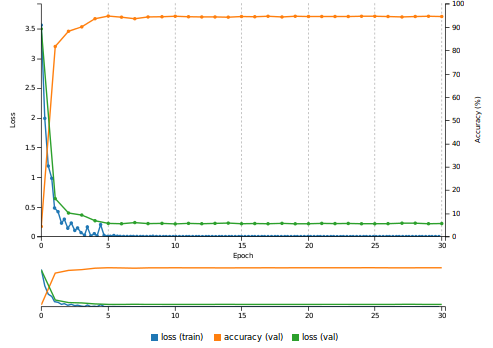
Попробовал ваши данные на Lenet используя DIGITS(caffe как бэкэнд), получилось что то положительное даже просто обучив на 80% этих данных, точность 94%, наверно можно и больше если будет больше данных или если зафайнтюнится на MNIST.
Тут еще можно заметить, что разные буквы в разном количестве, неплохо бы сделать чтобы кол-во было одинаковое.
Confusion matrix (тут я дал дурацкие имена буквам т.к. DIGITS не переваривает кирилицу)
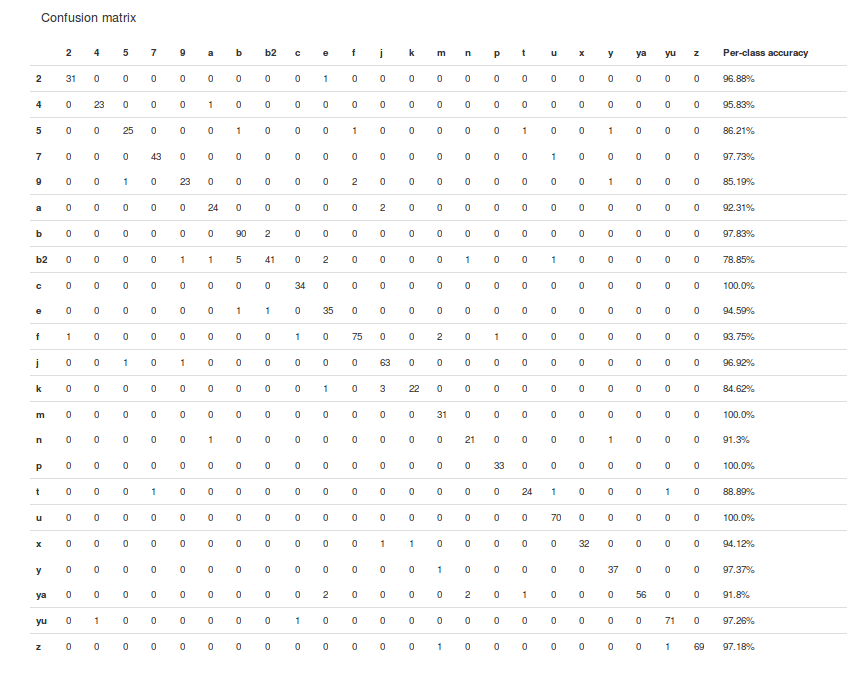
График обучения.
-
Тут подробнее расписано GoogleLeNet FCN
https://devblogs.nvidia.com/parallelforall/detectnet-deep-neural-network-object-detection-digits/
-
А как apollocaffe поможет?
а увидел, типа он может из numpy array получать данные.
Вроде как обычный caffe тоже так умеет через MemoryDataLayer
-
А как это работает
FIND_PACKAGE(OpenCV)
OpenCV должен быть установлен каким то специальным образом? на линуксе через apt-get?
-
Ну в хедере не написано как называется конкретная библиотека типа -lopencv_core
А как CMake облегчает жизнь? Можете скинуть template для opencv проекта?
-
Eсть ли какой то пример обучения сети без создания базы leveldb\lmdb, по идее это можно сделать через
ImageDataLayer\MemoryDataLayer?Есть пример как сделать forward passhttps://github.com/BVLC/caffe/blob/master/examples/cpp_classification/classification.cpp
Но непонятно должен ли при этом первый слой сети и последний иметь какой то специальный тип?
https://github.com/BVLC/caffe/blob/master/examples/cpp_classification/classification.cpp#L150
-
вот еще странный код
https://github.com/BVLC/caffe/blob/master/examples/cpp_classification/classification.cpp#L144
по сути по mean image считают среднее и вычитают, а не сам mean image.
-
Ну мой user case тут такой:
Поиск в хедерах чтобы понять что такая ф-ия есть в opencv, по идее можно еще и по сорцам искать, но я обычно использую поиск на гитхабе.
Поиск внутри либ для того чтобы понять какую либу надо включать для использования ф-ии, или можно не парится и включать вообще все либы opencv ? при линковке возьмется только нужное, размер файла не увеличится? т.е. тогда будет один Makefile на все проекты.
А вообще эта тема всплыла когда я пытался собирать легаси opencv проекты и была куча undefined reference на старые ф-ии, но дело было не в том, что они отсуствуют, а в том что в Makefile важен порядок.
UMDFace
в OpenCV
Опубликовано · Report reply
Еще такая штука есть
https://www.microsoft.com/en-us/research/project/msr-image-recognition-challenge-irc/
https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/