
maxfashko
-
Количество публикаций
86 -
Зарегистрирован
-
Посещение
-
Days Won
2
Сообщения, опубликованные пользователем maxfashko
-
-
Добрый вечер. Провел тесты следующего кода, в котором реализован ресайз фото на процессоре и видеокарте. Оборудование следующее:
Intel® Core™ i5-4670 CPU @ 3.40GHz × 4
GeForce GTX 650/PCIe/SSE2 2Gb GDDR5
Ubuntu 12.04 x64
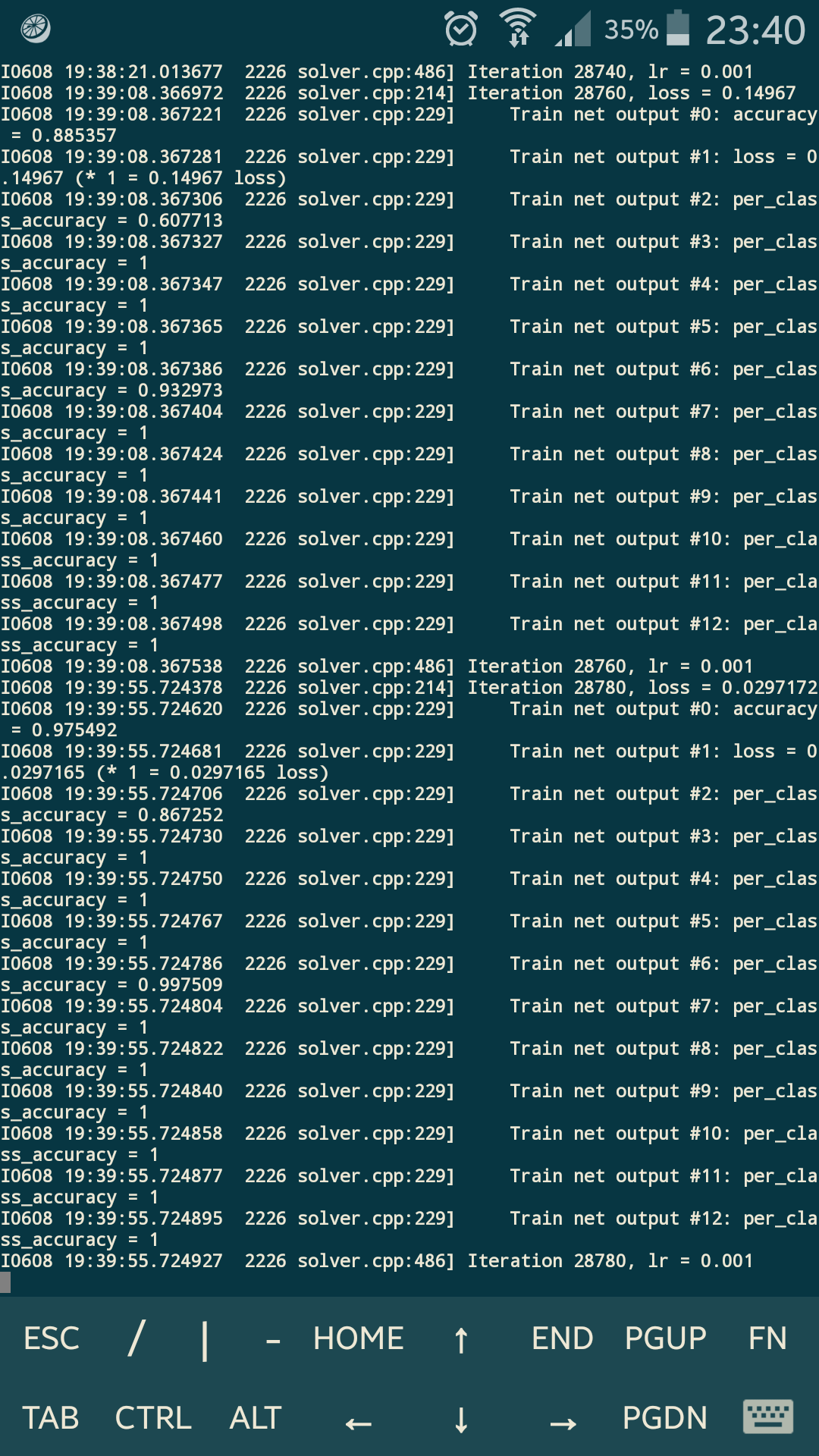
Результаты грустные:
gpu 0.4890(sec) / 2.0448(fps)
cpu 0.1623(sec) / 6.1632(fps)Неужели gtx 650 очень дрова?
Та же ситуация обстоит с pycuda. Тестовый скрипт ( https://wiki.tiker.net/PyCuda/Examples/SimpleSpeedTest ) выводит следующее время:
Using nbr_values == 8192
Calculating 100000 iterations
SourceModule time and first three results:
0.080705s, [ 0.005477 0.005477 0.005477]
Elementwise time and first three results:
0.161862s, [ 0.005477 0.005477 0.005477]
Elementwise Python looping time and first three results:
0.780193s, [ 0.005477 0.005477 0.005477]
GPUArray time and first three results:
3.765418s, [ 0.005477 0.005477 0.005477]
CPU time and first three results:
2.716871s, [ 0.005477 0.005477 0.005477]#код ресайза фотографий
#include <iostream> #include "opencv2/imgproc.hpp" #include "opencv2/highgui.hpp" #include "opencv2/calib3d.hpp" #include "opencv2/cudalegacy.hpp" #include "opencv2/cudaimgproc.hpp" #include "opencv2/cudaarithm.hpp" #include "opencv2/cudawarping.hpp" #include "opencv2/cudafeatures2d.hpp" #include "opencv2/cudafilters.hpp" #include "opencv2/cudaoptflow.hpp" #include "opencv2/cudabgsegm.hpp" #include "opencv2/imgproc/imgproc.hpp" #include "opencv2/opencv.hpp" using namespace std; using namespace cv; using namespace cv::cuda; void ProccTimePrint( unsigned long Atime , string msg) { unsigned long Btime=0; float sec, fps; Btime = getTickCount(); sec = (Btime - Atime)/getTickFrequency(); fps = 1/sec; printf("%s %.4lf(sec) / %.4lf(fps) \n", msg.c_str(), sec, fps ); } void processUsingOpenCvGpu(string input_file, string output_file); void processUsingOpenCvCpu(std::string input_file, std::string output_file); int main(){ processUsingOpenCvGpu("/home/maksim/Изображения/1.jpg", "/home/maksim/Изображения/1_rG.jpg"); processUsingOpenCvCpu("/home/maksim/Изображения/1.jpg", "/home/maksim/Изображения/1_rC.jpg"); return 0; } void processUsingOpenCvGpu(string input_file, string output_file) { unsigned long AAtime=0; AAtime = getTickCount(); //Read input image from the disk cv::Mat inputCpu = cv::imread(input_file,CV_LOAD_IMAGE_COLOR); cv::cuda::GpuMat input (inputCpu); if(input.empty()) { cout<<"Image Not Found: "<< input_file << endl; return; } //Create output image cv::cuda::GpuMat output; cv::cuda::resize(input, output, cv::Size(), .05, 0.05, CV_INTER_AREA); // downscale 4x on both x and y ProccTimePrint(AAtime , "gpu"); cv::Mat outputCpu; output.download(outputCpu); cv::imwrite(output_file, outputCpu); input.release(); output.release(); } void processUsingOpenCvCpu(std::string input_file, std::string output_file) { unsigned long AAtime=0; AAtime = getTickCount(); //Read input image from the disk Mat input = imread(input_file, CV_LOAD_IMAGE_COLOR); if(input.empty()) { std::cout<<"Image Not Found: "<< input_file << std::endl; return; } //Create output image Mat output; cv::resize(input, output, Size(), .05, 0.05, CV_INTER_AREA); // downscale 4x on both x and y ProccTimePrint(AAtime , "cpu"); imwrite(output_file, output); }
-
Все понял. Родная caffe-segnet не поддерживает multiple gpu. Что-то там изменили.
-
Приветствую. Может быть у кого-то есть идеи по поводу следующей проблемы?
Вот тут парень выложил caffe-segnet для задействовано нескольких gpu. https://github.com/developmentseed/caffe/tree/segnet-multi-gp
Я собрал, запустил обучение на трех tesla m2090, но прироста скорости не заметил, 20 итераций по-прежнему выполняются около 40 секунд. К тому же я думал что при использовании нескольких gpu память будет шариться, и я смогу увеличить batch size. Но сеть ведет себя странно:
| NVIDIA-SMI 352.39 Driver Version: 352.39 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. ||===============================+======================+======================|| 0 Tesla M2090 Off | 0000:19:00.0 Off | 0 || N/A 59C P12 30W / 225W | 10MiB / 5375MiB | 0% Default |+-------------------------------+----------------------+----------------------+| 1 Tesla M2090 Off | 0000:1A:00.0 Off | 0 || N/A 59C P1 139W / 225W | 4812MiB / 5375MiB | 87% Default |+-------------------------------+----------------------+----------------------+| 2 Tesla M2090 Off | 0000:1E:00.0 Off | 0 || N/A 59C P0 159W / 225W | 4457MiB / 5375MiB | 19% Default |+-------------------------------+----------------------+----------------------+| 3 Tesla M2090 Off | 0000:1F:00.0 Off | 0 || N/A 59C P0 141W / 225W | 4457MiB / 5375MiB | 0% Default |+-------------------------------+----------------------+----------------------+Я попытался попытался изменить batch size в segnet_train.prototxt (на m2090 работает только при значении 1, так как всего 5 gb ram) на значение 2 или 3. Но получил сообщение о нехватке памяти.Подскажите пожалуйста, могу ли я увеличить скорость обучения при использовании двух и более gpu? Если да, то что мне необходимо для этого сделать? Могу ли я увеличить upsample layer в segnet_train.prototxt чтобы память шарилась?layer { name: "upsample5" type: "Upsample" bottom: "pool5" top: "pool5_D" bottom: "pool5_mask" upsample_param { scale: 2 upsample_w: 30 upsample_h: 23 } } Я хочу изменить значения upsample_w : 45, upsample_h : 45 для того чтобы нейросеть могла принять на вход изображения 720*720. Возможно ли будет сделать это используя два и более gpu? -
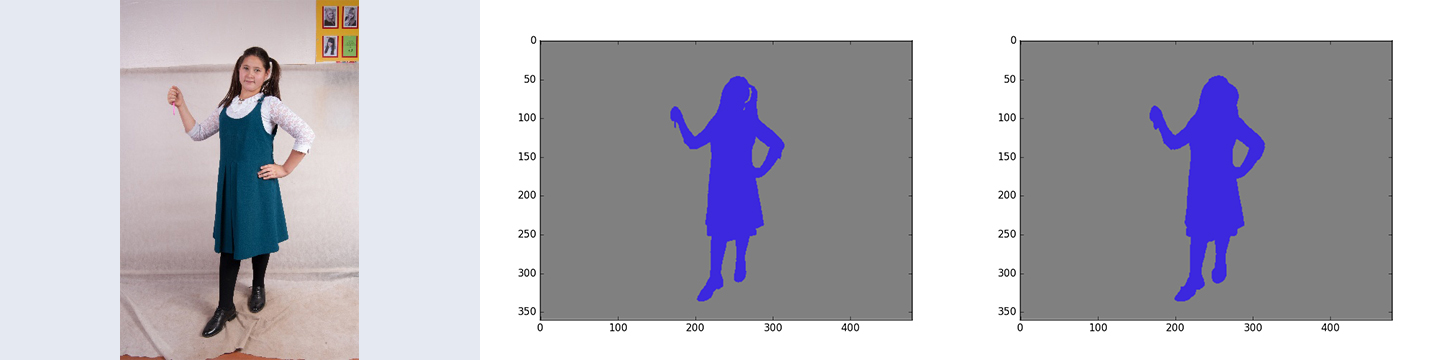
Программа будет работать с объектами сфотографированными на белом, сероватом фоне. На примере ниже исходное фото, ручная разметка, сегментированное фото. Точность для данного примера составляет 0.997627852057
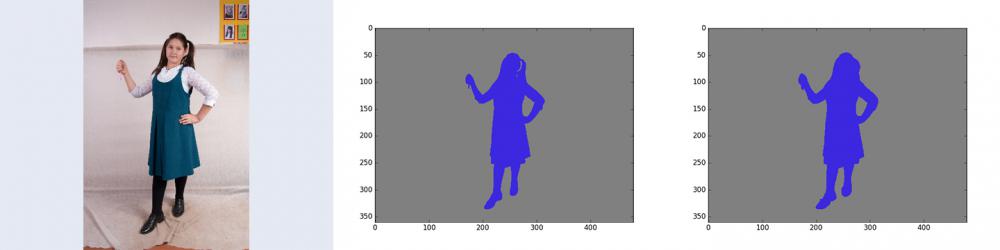
Исходное фото было "доведено" искусственно до размера 480х360. Надеюсь это не сильно влияет на результат.
-
Smorodov, в общем реализовал скрипт, расчитывающий accuracy:
Только вот в результате не уверен, слишком высокую точность выдает: accuracy = 0.996942198369 на изображении приведенном выше
1. В цикле подсчитываем кол-во P,N пикселей текущего изображения.
2. В цикле подсчитываем кол-во TN,TP пикселей текущего изображения, если текущий пиксель имеет одинаковое значение в изображениях ground_truth и segment
Взгляните пожалуйста на код:
from PIL import Image import numpy as np import matplotlib.pyplot as plt import os from os import listdir from os.path import isfile, join labelPath = 'test/ground_truth' segmentPath = 'test/segment' resultFileName = 'test/result.txt' labelList = [] segmentList = [] resultArr = [] colorClass1 = (60,40,222) #object colorClass2 = (128,128,128) #background #get files in dir def list_files(path, files): # returns a list of names (with extension, without full path) of all files # in folder path for name in os.listdir(path): if os.path.isfile(os.path.join(path, name)): files.append(name) return files def main(): #for calculation global value mean = 0 TP_g = 0 TN_g = 0 P_g = 0 N_g = 0 list_files(labelPath, labelList) list_files(segmentPath, segmentList) if len(labelList) != len(segmentList): print 'len '+labelPath+' != '+segmentPath return -1 for i in range (len(labelList)): TP = 0 TN = 0 P = 0 N = 0 #label img imgLabel = Image.open(labelPath+'/'+labelList[i]) w = imgLabel.size[0] #Определяем ширину. h = imgLabel.size[1] #Определяем высоту. pixLabel = imgLabel.load() #Выгружаем значения пикселей. #segment img imgSegment = Image.open(segmentPath+'/'+segmentList[i]) pixSegment = imgSegment.load() #Выгружаем значения пикселей. #calculate P, N (pixels of object and background) for k in range(0, w): for l in range(0, h): if pixSegment[k,l][0:3] == colorClass1: P+=1 if pixSegment[k,l][0:3] == colorClass2: N+=1 #calculate TP and TN (пиксели классифиц. как объект и явл. им) for k in range(0, w): for l in range(0, h): if pixLabel[k,l][0:3] == colorClass1 and pixSegment[k,l][0:3] == colorClass1: TP+=1 if pixLabel[k,l][0:3] == colorClass2 and pixSegment[k,l][0:3] == colorClass2: TN+=1 TP_g += TP TN_g += TN P_g += P N_g += N #calculate accuracy for current image currentAcc = float(TP+TN) / float(P+N) resultArr.append(str(i)+' accuracy = '+str(currentAcc)) print str(i)+' accuracy = '+str(currentAcc) #calculate mean global accuracy mean = float(TP_g+TN_g)/float(P_g+N_g) print 'Mean accuracy = '+str(mean) resultArr.append('Mean accuracy = '+str(mean)) #write result resultFile = open(resultFileName, 'w') for item in resultArr: resultFile.write("%s\n" % item) main()
-
2 часа назад, Smorodov сказал:Начать можно отсюда: https://en.wikipedia.org/wiki/F1_score
")
И это пригодится: https://en.wikipedia.org/wiki/Precision_and_recall
Именно accuracy=(TP+TN)/(P+N), но это не самая объективная метрика.
Спасибо! Поделитесь пожалуйста, что означают P, N ?
Как я понял TP - это объект (синий), пиксели, которые верно сегментированы
TN - это фон (серый), пиксели, которые верно сегментированы
P, N - это кол-во файлов?
То есть проходим циклом по картинке забирая хорошие "синие" пиксели. Затем так же но берем уже хорошие "серые" пиксели? Складываем и делим на кол-во?
-
Добрый вечер. Интересует собственно как расчитывать точность на сегментированных нейронной сетью изображениях? Имеем тестовую выборку, пропущенную через нейронную сеть, в которой есть файлы разметки и собственно файлы сегментированные сетью. Теперь как мы можем по полученным изображениям выяснить их точность? Понятное дело, что сегментированные файлы должны стремиться к изображениям аннотации. Написал следующий скрипт для расчета точности:
#!/usr/bin/env python # -*- coding: utf-8 -*- # vim:fileencoding=utf-8 #use only 2 classes # object (60,40,222) color from PIL import Image import numpy as np import matplotlib.pyplot as plt import os from os import listdir from os.path import isfile, join labelPath = 'test/ground_truth' segmentPath = 'test/segment' resultFileName = 'test/result.txt' labelList = [] segmentList = [] resultArr = [] #get files in dir def list_files(path, files): # returns a list of names (with extension, without full path) of all files # in folder path for name in os.listdir(path): if os.path.isfile(os.path.join(path, name)): files.append(name) return files def main(): mean = 0 list_files(labelPath, labelList) list_files(segmentPath, segmentList) if len(labelList) != len(segmentList): print 'len '+labelPath+' != '+segmentPath return -1 for i in range (len(labelList)): #label img imgLabel = Image.open(labelPath+'/'+labelList[i]) w = imgLabel.size[0] #Определяем ширину. h = imgLabel.size[1] #Определяем высоту. pixLabel = imgLabel.load() #Выгружаем значения пикселей. #segment img imgSegment = Image.open(segmentPath+'/'+segmentList[i]) pixSegment = imgSegment.load() #Выгружаем значения пикселей. amountPixObjLabel = 0 amountPixLossLabel = 0 #amount pixels with object for k in range(0, w): for l in range(0, h): if pixLabel[k,l][0:3] == (60, 40, 222): #blue color object amountPixObjLabel+=1 #search differences for k in range(0, w): for l in range(0, h): if pixLabel[k,l][0:3] != pixSegment[k,l][0:3]: amountPixLossLabel +=1 #one pix = % onePix = float(100) / float(amountPixObjLabel) count = 100 - (amountPixLossLabel*onePix) mean += count resultArr.append(str(i)+' accuracy = '+str(count)) print str(i)+' accuracy = '+str(count) print 'Mean accuracy = '+str(mean / len(labelList)) resultArr.append('Mean accuracy = '+str(mean / len(labelList))) #write result resultFile = open(resultFileName, 'w') for item in resultArr: resultFile.write("%s\n" % item) main()Смысл такой: загружаем значения пикселей аннотированного изображения, затем делаем тоже самое с сегментированным изображением. Если в сегментированном изображении текущий пиксель отличается от пикселя в аннотированном, увеличиваем счетчик ошибочных пикселей по данному изображению. Затем расчитываем сколько пикселей составляет один процент от всех пикселей в объекте аннотированного изображения. И затем переводим наши ошибочные пиксели в проценты. Это и будет наша точность.
file: ground_truth
.
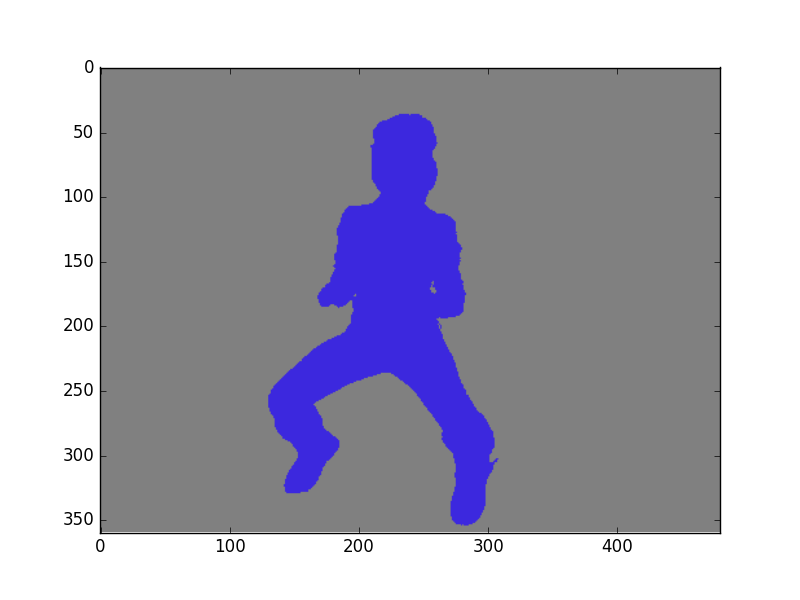
file: segment
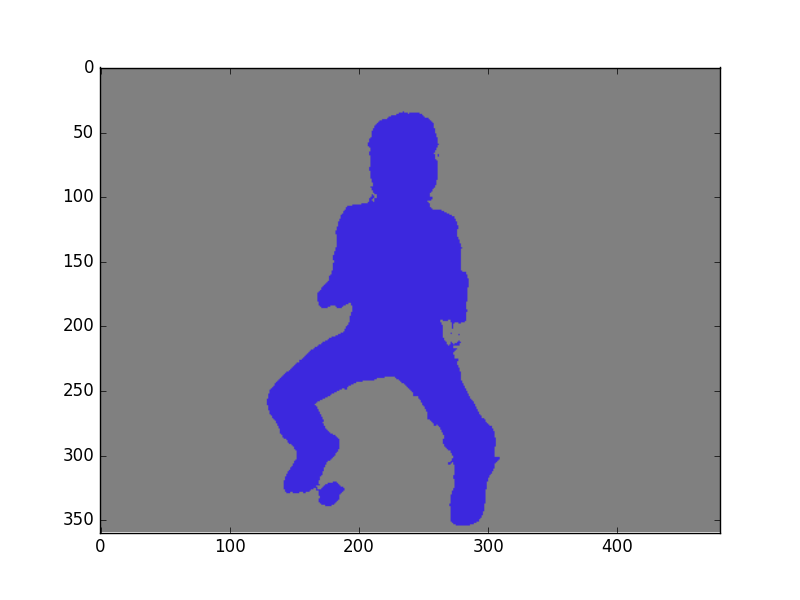
Например для данного сообщения выводится значение accuracy = 96.9656336161
-
В 04.07.2016 at 22:08, Smorodov сказал:Тут надо смотреть на тестовую выборку, если точность на ней повышается, то почему бы и не поучить.
Smorodov, насчет теста, я правильно подхожу к тестированию? Делаю следующим образом:
В качестве модели указываю ту, на которой тренировался (segnet_train.prototxt)
~/PassArtSegment/Segnet/caffe-segnet/build/tools/caffe test -gpu 0 -model ~/PassArtSegment/SegNet-Tutorial/Models/segnet_train.prototxt - weights ~/PassArtSegment/SegNet-Tutorial/Models/Training/segnet_iter_40000.caffemodel -iter 3000 2>&1 | tee test.logПосле чего парсим лог и получаем следующие графики точности и ошибки:
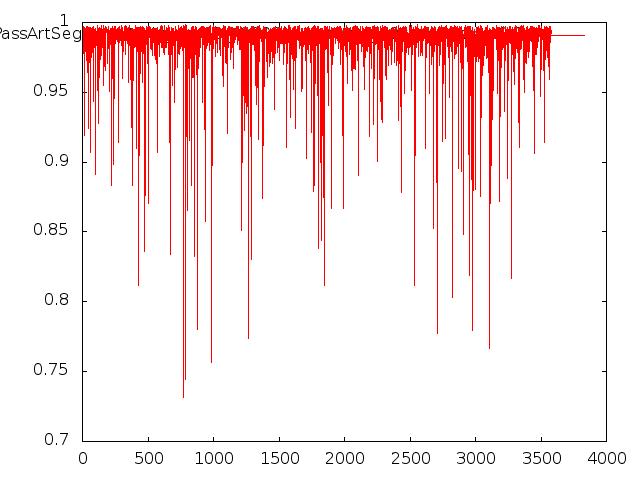
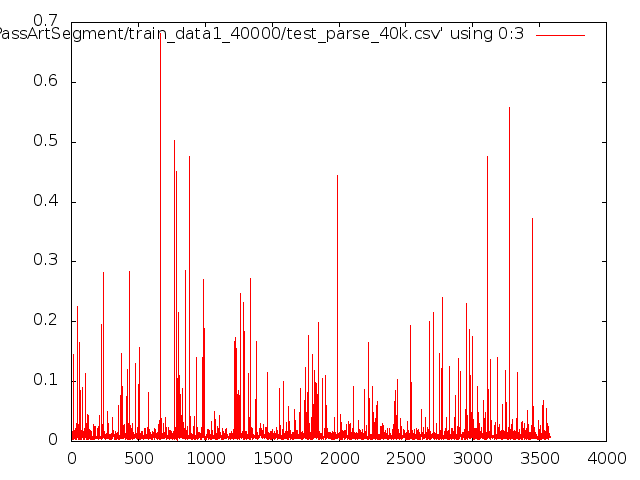
Ну и если высчитать средние значения из лога то получаю:
columnNumber = 2 data = [float(l.split(',')[columnNumber]) for l in open('log.csv', 'r').readlines()] mean = sum(data) / len(data) print(mean) //0.98666 для точности columnNumber = 3 data = [float(l.split(',')[columnNumber]) for l in open('log.csv', 'r').readlines()] mean = sum(data) / len(data) print(mean) //0.013902 для ошибкиЭто верный подход?
-
11 минуту назад, Smorodov сказал:Это нормально, данные берутся порциями, на одних порциях ошибка одна, на других другая, вот и пляшет.
В процессе обучения, по мере улучшения модели, этот забор уменьшается.
Спасибо! Думаете есть смысл обучать более 40к итераций?
-
Товарищи! Есть кто живой?) Кто-нибудь может мне подсказать по поводу кривых обучения?
-
14 часа назад, BeS сказал:Сейчас выгодней купить 1080-ю, чем оплачивать тачки в амазоне (GPU + жесткий диск на амазоне стоят не оправдано дорого).
Понятно.
Хочу еще спросить - официальный туториал segnet говорит, что после обучения сети, необходимо проделать следующее:
python /Segnet/Scripts/compute_bn_statistics.py /SegNet/Models/segnet_train.prototxt /SegNet/Models/Training/segnet_iter_10000.caffemodel /Segnet/Models/Inference/ # compute BN statistics for SegNetpython /SegNet/Scripts/test_segmentation_camvid.py --model /SegNet/Models/segnet_inference.prototxt --weights /SegNet/Models/Inference/test_weights.caffemodel --iter 233 # Test SegNetПосле этих команд выводятся изображения из тестовой выборки и результаты сегментации.
А собственно можно просто взять обученную *.caffemodel и сегментировать любое изображение, после чего сохранить его в указанной директории?
Все таки удалось запустить SegNet на одной m2090
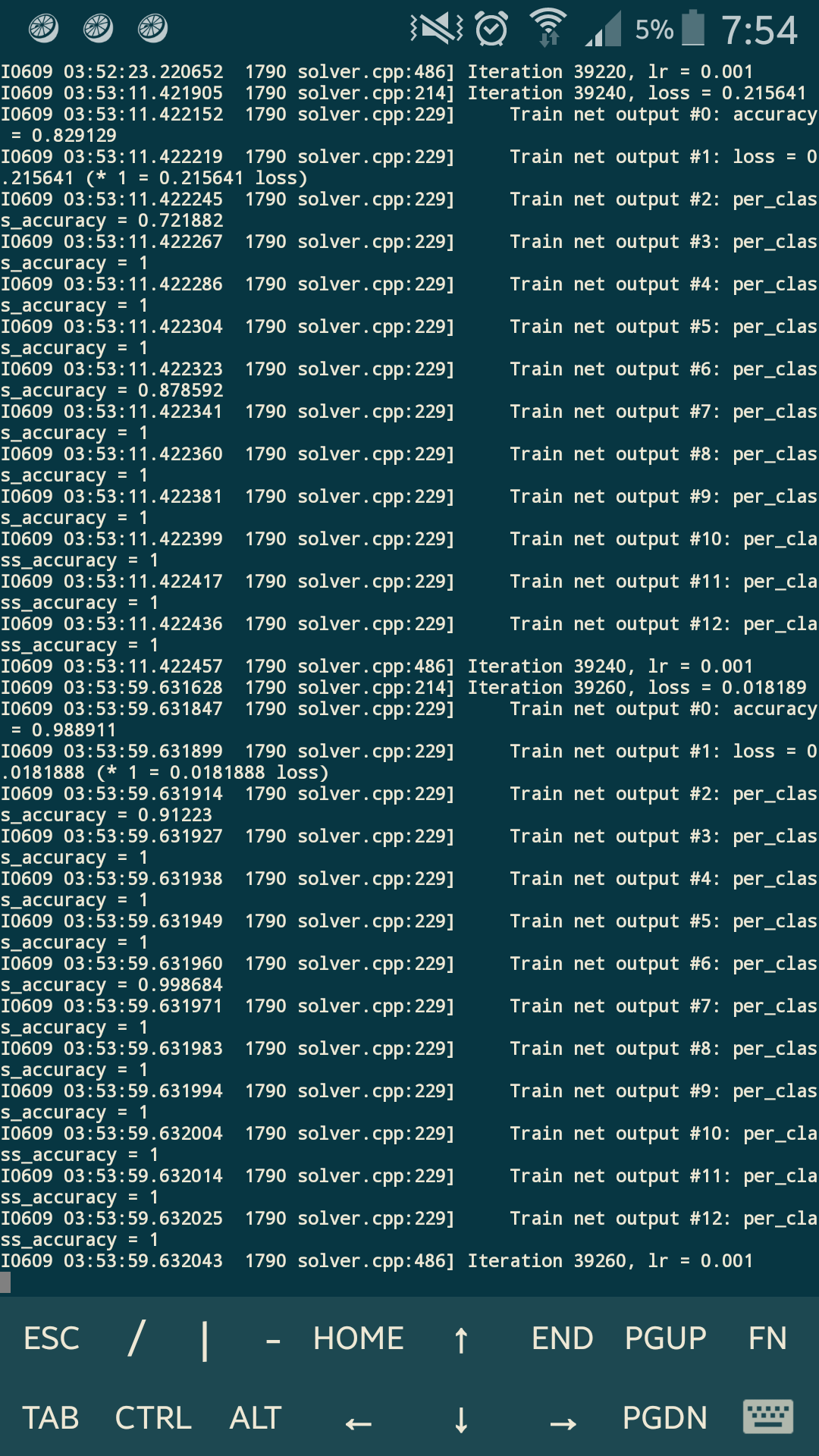
А вообще это нормально, что у меня обучение происходит вот так? Уже после 3000 итерации точность довольно неплохая, ошибка тоже небольшая.
И еще - подскажите, из-за чего вот эти всплески ошибок происходят? На итерациях 5, 10, 15 тыс. Они ведь получились эквивалентны графику accuracy на тех же итерациях. Это из-за каких-то уникальных особенностей в обучающей выборке - неточности, выбросы и т.д ? Как от них избавиться? Или это нормально?
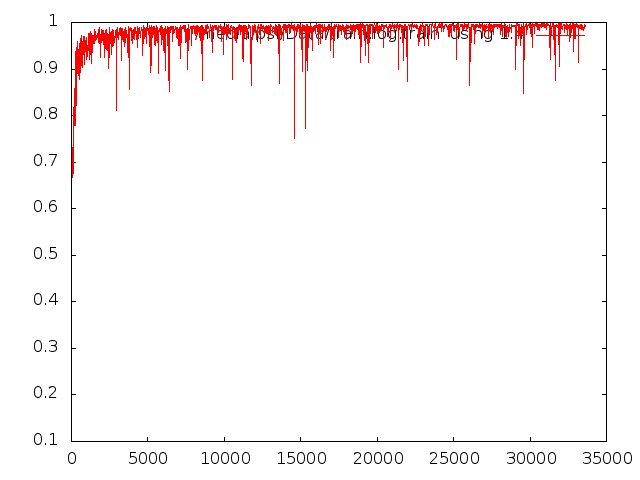
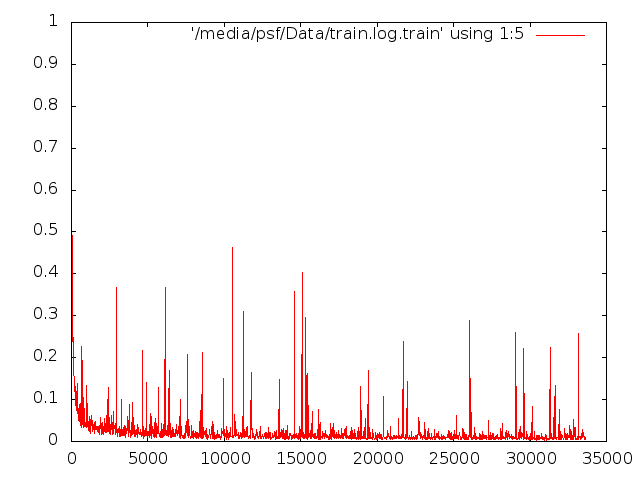
-
День добрый!
А что еще можно попробовать для обучения сетки на сегментацию? Сейчас у меня имеется в распоряжении 4 Tesla m2090 (но это только 5 gb на каждой карточке). Tesla m40 больше не доступна, и врядли в обозримом будущем удастся получить к ней доступ.
Как я понимаю на m2090 я не запущу SegNet. Пробывал указать все 4 карты при тренировке ( -gpu 0,1,2,3 ) не понимает. Может на амазоне есть инстансы с карточками по 10 gb и выше памяти? Я что-то не понял тамошних порядков с техническими характеритиками кластеров.
-
Цвета разметки брал отсюда http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html. По сути ребята модель тренировали на данном датасете, если я ничего не путаю.
Зачем изобретать велосипед
-
А каким-нибудь образом можно получить кривую зависимостей loss и accuracy имея только обученную модель, но не имея лога?
Сейчас переучить не получиться - кластер с м40-вой только на 2 дня погонять давали.
В общем обучение можно считать проваленным:
При конвертации размеченных цветами аннотированных изображений в {0,1}, в алгоритм закралась ошибка. Какая-то часть данных была размечена как 1- объект 0-фон, а другая чать как 0-объект, 1-фон. Этим объясняется странное поведение при тренировке: две итерации могли идти с точностью в 0.95, а следующие за ней десять итераций, как 0.20, и так до 40000 итерации.
Бедняга, все не могла понять, что же от нее хотят


-
У меня действительно всего 2 класса, ptototxt я не редактировал. Когда запустил обучение поздно обнаружил, что неверно указал лог, и обучение не фиксировалось в логе. По этому я просматриваю не log а подключаясь к кластеру через screen чтобы посмотреть что там творится.
Из-за того, что не отредактировал prototxt все обучение на смарку?
-
После 10к итераций результат не улучшился, значит ли это, что обучение можно останавливать?
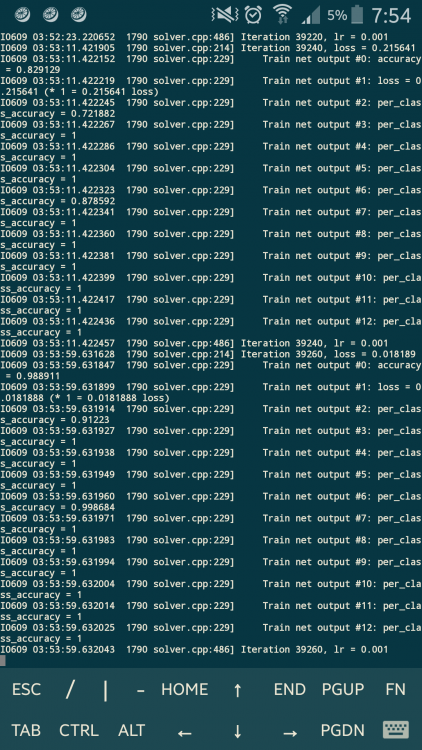
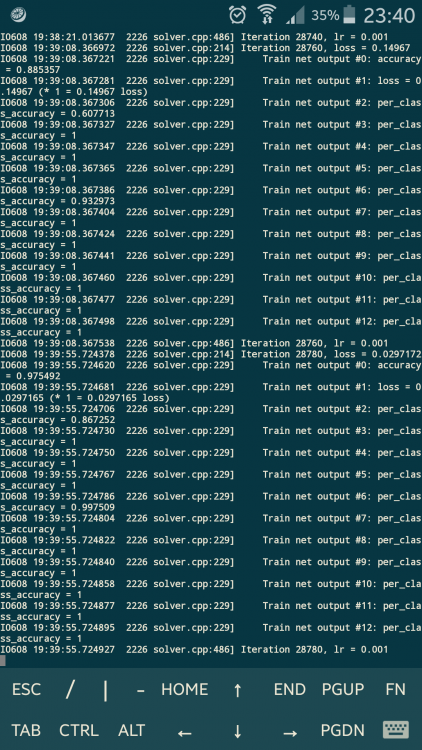
Я понимаю так, что меня должны интересовать следующие строки:
rain net output #0: accuracy = 0.987271
Train net output #2: per_class_accuracy = 0.967589
Train net output #6: per_class_accuracy = 0.987386
Iteration 40580, loss = 0.0586965
И если показатели хорошие, то останавливать обучение?
-
Спасибо! Именно это помогло! Кому нужно - в репозитории имеется около 3к идеально размеченных автоматом данных (больший объем пока не делал)
А что с настройками обучения? Оставить все по дефолту? 40к итераций хватит? если у меня будет 10-30к изображений для тренировки? Как выявить наилучший результат при тренировке?
-
 2
2
-
-
Приветствую! Расскажу немного о своих трудностях, с которыми я столкнулся при обучении данной сетки:
На Tesla m40 пример, приведенный в туториале обучается очень здорово и шустро - все ок!
Когда же пытаемся всунуть сетке свои размеченные изображения -
F0606 19:20:16.349822 2152 math_functions.cu:123] Check failed: status == CUBLAS_STATUS_SUCCESS (11 vs. 0) CUBLAS_STATUS_MAPPING_ERROR
Уперся в стену с созданием файлов "png" аннотации-масок. Как я понимаю обычное RGB изображение "png" нам необходимо перекодировать в градации серого + какой-то режим типо HSV. Предварительно его раскрасив необходимыми цветами:
64 128 64 Animal
192 0 128 Archway
0 128 192 Bicyclist
0 128 64 Bridge
128 0 0 Building
64 0 128 Car
64 0 192 CartLuggagePram
192 128 64 Child
192 192 128 Column_Pole
64 64 128 Fence
128 0 192 LaneMkgsDriv
192 0 64 LaneMkgsNonDriv
128 128 64 Misc_Text
192 0 192 MotorcycleScooter
128 64 64 OtherMoving
64 192 128 ParkingBlock
...
0 0 0 VoidНо как бы не пытался я это сделать в Photoshop, у меня не выходит. Сеть не хочет это кушать.
Единственное решение, которое может создавать файлы масок-аннотаций - https://github.com/kyamagu/js-segment-annotator
После этой тулзы сеть съедает файлы "png" и обучается. Но проблема в том, что мне не нужно размечать данные вручную. У меня уже имеются "вырезанные" файлы. Мне остается только наложить "вырезанные" поверх "исходных" jpg и залить цветами. Но как конвертировать в цвета, которые сеть будет воспринимать и обучаться?
RGB разных цветов - отказ
Градации серого 25% - отказ
Индексированные цвета (3 цвета) - отказ
Еще нашел вот такой скрипт, который вроде как должен решить мою проблему, но сеть тоже не ест файлы, которые выходят после скрипта. (Более того, сеть даже не ест файлы аннотации из "родного" датасета CamVid, если ее прогнать через данный скрипт)
Как мне это победить?
-
mrgloom, да, из-за появления зубчатости.
То есть как я понимаю, если я не имею под рукой штук 5 tesla k40 я не продвинусь ни на шаг в своей проблеме?
-
Снова здравствуйте. Насколько сложно изменить структуру той же segnet для того чтобы у меня изображение на выходе (а может и на входе при обучении) было не 360*480 пикселей, а к примеру 1000*1500. Так как с изображением 360*480 невозможно работать, хочу увеличить размерность выходного изображения. Простой ресайз ясное дело никакой пользы не принесет. Как при этом мне необходимо действовать? И нужно ли менять структуру сетки?
-
В 14.03.2016 at 15:29, mrgloom сказал:https://github.com/alexgkendall/SegNet-Tutorial/blob/master/Example_Models/segnet_model_zoo.md
вообще не очень понятно при размере базовых моделей в ~5Mb на что тратится основная память?
Вот еще кстати наткнулся про память https://github.com/fmassa/optimize-net
Можете попробовать на CPU запустить обучение? можно не целиком, а только несколько итераций чтобы проверить что оно в целом работает, а то у меня не работает.
На CPU получилось запустить на обучение segnet_basic_train.
На macbook i7 / vmware Ubuntu на 20 итераций тратится около 10 минут. На osx собрать segnet caffe не получилось (вылезла куча ошибок).
Так же на Ubuntu не получается запустить пример
python /home/myuser/Downloads/SegNet/SegNet-Tutorial/Scripts/compute_bn_statistics.py /home/myuser/Downloads/SegNet/SegNet-Tutorial/Models/segnet_basic_train.prototxt /home/myuser/Downloads/SegNet/SegNet-Tutorial/Models/Training/segnet_basic_camvid.caffemodel /home/myuser/Downloads/SegNet/Models/Inference/Выводит ошибку
F0225 23:41:36.745960 11302 syncedmem.cpp:51] Check failed: error == cudaSuccess (8 vs. 23)Есть у кого мысли в чем может быть причина?
-
Друзья, а как мне создать выборку и разметить ее для обучения?
Я должен взять png изображения и сделать из них jpeg изображения предварительно раскрасив их в 2 цвета (фон и объект). А затем перевести все это дело в вектор и подать на вход нейросети?
-
12 минуты назад, BeS said:Под такой объем если только FTP поднимать. Ну или на каком-нибудь rutracker'е в виде торрент-раздачи выложить. Думаю, для тренировки сеток такое было бы крайне полезно.
з.ы. кстати, вспомнил, у DeepLab есть онлайн-сервис, где можно залить свою картинку и посмотреть. как он будет её сегментировать: http://www.robots.ox.ac.uk/~szheng/crfasrnndemo
В общем и целом это возможно, почему нет? Как появиться время обязательно расшарю образы!
По сервису - результат неплохой - в некоторых тестах хуже, в некоторых лучше того, чем сейчас пользуюсь.
Из поставки opencv перепилил под себя grabcut для автоматической, пакетной сегментации фотографий. Прямоугольник объекта задаю в настройках условно - примерно 10-15% от краев изображения. Результат неплохой, учитывая участие человека в процессе на уровне "нажал кнопку - смотришь на результат".
Bes, в обучении я ноль. Только один раз учил каскад для обнаружения лиц adaBoost`ом. С чего начать, чтобы натренировать данную систему?
Возможно ли добиться лучших результатов с моим большим кол-вом изображений, чем это сделали ребята из лаборатории?
-
Спасибо, посмотрю по этой теме.
На самом деле 50к - это не предел. Если перетрясти все сервера, думаю можно и в втрое большее кол-во наскрести(png). Обычные фото (jpg) никогда не исчислял!
Можно, только куда залить терабайт? Или даже половину от этого?

cpu быстрее gpu
в OpenCV
Опубликовано · Report reply
Smorodov, вы как всегда правы. Установка девайса помогла снизить время, но по-прежнему, процессор чуть быстрее.
Gpu 0.1892
Cpu 0.1600
Дело в том, что программа построена так, что процесс ресайза это не главное действие, после ресайза изображение поступает на дальнейшую обработку, там пакетной обработки даже нет. Только если создавать несколько потоков, и одновременно обрабатывать несколько изображений. Сначала класссификация, затем ресайз, после этого сегментация. И так каждое изображение в своем потоке?
Nuzhny, где это можно сделать? Подробнее пожалуйста.
Компилятор не может наложить какие либо особенности?
Компилировал nvcc resize.cpp -o resize 'pkg-config --cflags --libs opencv' -lopencv_gpu