
Андрей_Андрей
-
Количество публикаций
43 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные пользователем Андрей_Андрей
-
-
Над дорогой установлена камера с ик подсветкой. На фото наблюдаю непонятные артефакты - обведены на снимке. На разных фото они всегда в разных местах. Иногда они появляются над автомобилем, иногда перед ним, иногда их нет совсем. Но если они есть, то всегда недалеко от автомобиля. Что это такое может быть?

-
Спасибо, большое за ответ, теперь я сделал так:
python tf_text_graph_faster_rcnn.py --input hr_model_lstm.pb --config example.config --output hr_model_lstm.pbtxt
в качестве конфига взял # Faster R-CNN with Inception Resnet v2, Atrous version;
В ответ при импорте в
net = cv2.dnn.readNetFromTensorflow(weights, config)
получил ошибку: [libprotobuf ERROR D:\Build\OpenCV\opencv-3.4.4\3rdparty\protobuf\src\google\protobuf\text_format.cc:288] Error parsing text-format opencv_tensorflow.GraphDef: 13334:5: Unknown enumeration value of "20" for field "type".
раньше он ругался на значение DT_RESOURCE, теперь ругается на значение 20.
нода из pbtxt выглядит так:
node {
name: "lstm1_b/while/TensorArrayWrite/TensorArrayWriteV3/Enter"
op: "Enter"
input: "lstm1_b/TensorArray"
attr {
key: "T"
value {
type: 20
}
}
attr {
key: "_class"
value {
list {
s: "loc:@lstm1_b/while/mul_5"
}
}
}
attr {
key: "frame_name"
value {
s: "lstm1_b/while/while_context"
}
}
attr {
key: "is_constant"
value {
b: true
}
}
attr {
key: "parallel_iterations"
value {
i: 32
}
}
}что я не так делаю?
-
Коллеги, суть проблемы: не удается загрузить мной созданную модель tensorFlow в opencv.dnn методом
cv2.dnn.readNetFromTensorflow(weights,config)
выдается ошибка распарсивания графа вида Error parsing text-format opencv_tensorflow.GraphDef: 4059:5: Unknown enumeration value of "DT_RESOURCE" for field "type".
гугление приводит к рецептам вроде заморозьте граф, преобразуйте файл *.pbtxt с помощью файлов, входящих в opencv, конфиг для сети при этом скачайте по ссылке, везде рекомендации, примерно как тут: https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-APIвопрос: но ведь это-же для конкретной заранее спроектированной сети - mobilenet, rcnn, yolo и других известных, я правильно понимаю или нет?
и если да, то, что делать, если моя структура самописная? это не lenet, не guglonet, не yolo, это моя собственная сетка. мне что, не удастся ее в dnn прочитать?
Спасибо.
-
В 25.07.2017 at 11:48, Nuzhny сказал:Чего не хватает?
GRU не хватает. я так понимаю тема давно поднималась, но не хватает до сих пор...
-
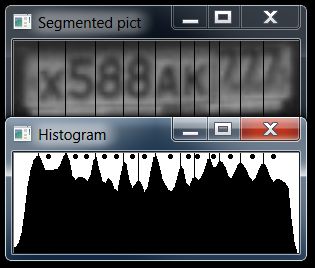
нет, это не скользящее окно. это символы автомобильного номера, разделенные по градиенту яркости вдоль широкой стороны номера.
в целом все хорошо, но есть символы, которые этим алгоритмом режутся пополам ( м, н, 8, 6 ) - у всех них есть ложный максимум гистограммы яркости посередине, довольно большой, простым сравнением с соседними надежно отфильтровать его не удается. А для буквы М он даже выше чем соседние максимумы. И вот дилемма - то-ли это 2 цифры "1"? то-ли одна буква "м"... вот как-то так.
вроде питонская библиотека sklearn.svm обучает классификатор с возможностью определять вероятность, но эта либа не для С++.
Ищу аналог. вот народ вроде про аналоги пишет: https://stackoverflow.com/questions/11378819/scikit-learn-equivalent-for-cне знаю во что у меня все эти приседания выльются в плане быстродействия...
-
Коллеги, огромное спасибо за Ваши комментарии.
Насколько я понимаю, получить значение функции для классификации у меня нет вариантов, бо я распознаю 22 символа (буквы и цифры) и это никак не бинарная классификация. У меня нет проблемы, что получить из алгоритма - надежность (confidence) или вероятность (probability) - мне хоть-бы что-нибудь заиметь, уже было-бы неплохо, т.к. сейчас нет вообще ничего. Из описания упомянутого mrgloom'ом в предыдущем посте хака, я вынес только то, что все сказанное справедливо только для бинарной классификации, что не есть мой случай.
Разбираюсь в упомянутом RVM.
Беда моя в том, что без достоверности (вероятности),в любом виде, ничего у меня не выйдет, т.к. у меня нет четких областей в которых я распознаю символ. а есть набор предположительно областей, каждую из которых я отправляю на распознавание и вот по достоверности( вероятности) хотел определять, что-же за символ на самом деле передо мной.
Что еще можно придумать, прежде чем отказаться от SVM в пользу другого алгоритма?
-
Похоже проблема в том, что я использую классификацию, CvSVM::C_SVC C-Support Vector Classification; а должен исп регрессию CvSVM::EPS_SVR \epsilon-Support Vector Regression. тогда predict вернет значение функции.
переучиваю каскад.UPD. predict стал возвращать float. но количество ошибок с 0.11% выросло до 74%... а новый *.dat файл
стал размером в 1 кБ вместо 6кБ у старого..что-то не так..
-
может у вас это getDecisionFunction()?
в opencv2 svm.predict(Mat img, true) должен мне возвращать это значение отражающее дистанцию от плоскости. но почему-то он мне возвращает label... Кто знает почему?
-
ну например значения векторов у меня такие: 0.055761, 0.0971997, 0.188256, 0.149404, 0.176307, 0.16017, 0.167007, 0.0969387
количество векторов - всегда 5650, сумма значений длин векторов для разных символов тоже одинаковая. Например для первого она вседа 536.1, для второго 634.7 и т.д. но эти цифры повторяются, для разных символов, в том числе для неправильно распознанных.
Я как-раз все и делаю на основе этого примера.Вот тут: http://www.recognition.mccme.ru/pub/RecognitionLab.html/methods.html#nonLinearSVM автор в разделе Уверенность классификации говорит о некоем значении классифицирующей функции, по которому можно судить о достоверности классификации. Где ее, эту функцию взять?
-
оох. Андрей Владимирович, расстояние не меняется ни в примере points_classifier, ни у меня в программе, и не зависит от параметра С. я ставил С =1000, и цифры суппорт вектора абсолютно такие-же вне зависимости даже от того, корректно распознался символ, или нет. Подскажите что еще можно подумать?
-
31 минуту назад, Smorodov сказал:Сетка строится по параметрам, которые вы задаете, возможно она в вашем (?) случае целочисленная.
Спасибо. запускаю points_classifier, разбираюсь.
svm.predict возвращает float, но десятичная часть всегда ==0 .
я не очень Вас понял - какой именно параметр из Вашего списка у меня может быть целочисленный?
я распознаю символы на картинке методом hog + svm
пробую выводить svm.get_support_vector(i) - для совершенно разных символов он мне выводит абсолютно одинаковые числа. -
дистанция до гиперплоскости меня абсолютно устроит. и в документации говорят, что, мол если returnDFVal = true, то predict ее и вернет . а у меня все равно int на выходе...
как мне ее (дистанцию) получить? -
да, но я ставлю returnDFVal = true
-
Коллеги, svm.predict возвращает мне int, вместо float. Я никак не могу оценить с какой достоверностью он мне распознает. Что я делаю не так?
код примерно такой (С++):vector <float>predicted_vector(img_vector.size());{
for (int i = 0; i < img_vector.size(); i++){
img_vector = symbRecognitor.deskew(img_vector); //наклон перед распознаванием
hists = symbRecognitor.preprocess_hog(img_vector); // hog
predicted_vector = svm.predict(hists, true);
....
}вот параметры:
SVMParams param;
param.kernel_type = SVM::POLY;
param.svm_type = SVM::C_SVC;
param.C = 1;
svm.load(datFilePath); -
я искал связанные контуры (findContours), оставлял из всех только символы ( по размеру и соотношению сторон), преобразовывал их в полигоны (approxPolyDP), и обводил их прямоугольниками (boundingRect) .
Потом строил прямую между левыми нижними углами прямоугольников в одной строке, и искал наклон (арктангенс разности по y / разность по x.), и потом этот наклон компенсировал.
Получилось хорошо. -
Здравствуйте.
Наша фирма занимается разработкой микропроцессорных встраиваемых систем.
Появились новые проекты, и нам требуется программист Python, C++Требования:
Уверенные знания Python, CPP, опыт разработки приложений под Windows, Linux от 2-х лет.
Опыт работы с opencv, уверенное знание основного функционала этой библиотеки.
Опыт работы с системой контроля версий, багтрекером (любыми)
Приветствуется опыт решения задач классификации объектов, использования нейронных сетей.Мы предлагаем:
Работу над проектами в области машинного зрения, систем "Умный город", интеллектуальных транспортных систем.
Дружный коллектив, спокойная, доброжелательная атмосфера.
Работа в офисе в 3 минутах ходьбы от метро Фонвизинская.
Полное соблюдение трудового законодательства РФ.
ЗП по результатам собеседования.Не агентство, прямой работодатель.
пишите: fader@mail.ru
-
1 померяйте соотношение ширины/высоты всех найденных прямоугольников.
2 отсейте все, у которых это соотношение получилось больше 1.1 ... 1.2
3 ???
4 Profit!
-
Сделал. Почитал инет и решил пока отложить сеть в сторону, и сделал распознавалку на hog+SVM. Получилось неплохо (0.11 % ошибок ) на 13300 картинок в символами. Пока меня устраивает, хотя сети изучать тоже конечно нужно.
-
Спасибо за ответ. вот тут: http://nordavind.ru/node/550 для моей задачи автор пишет :
" 625 нейронов во входном слое. Количество нейронов скрытых слоев нейронной сети обычно выбирается в 10-20 раз больше количества входных значений нейронной сети. Пусть наша нейронная сеть состоит из двух скрытых слоев. Первый скрытый слой состоит из 6000 нейронов (и 3,75 млн. связей с входным слоем), а второй из 3000 нейронов (и 18 млн. связей с первым скрытым слоем). "
18 млн связей - приличное количество. сколько -ж они учиться будут....
-
Здравствуйте, для распознавания символов на на номерном знаке автомобиля хочу применить нейронную сеть.
Читаю про "обычную" полносвязную НС. В качестве недостатка упоминается большое чисто ее элементов, и как альтернатива рассматривается сверточная сеть.
А она, наряду с DeepLearning вроде как относится к другому классу сетей. И вот думаю: действительно мне нужна сверточная НС, нужно-ли мне для задачи идентификации 22-х символов поднимать caffe или подобную серьезную систему,
или смотреть в сторону SVM.Сложно сориентироваться, т.к. у меня в этом деле нет опыта совсем.
Вообще входные требования - максимальная точность классификатора при условии что на входе будет картинка символа с различной яркостью, контрастностью, и четкостью монохромного (не бинаризованного, т.к. бинаризовать некоторые символы без существенного искажения не выходит)
изображения символа, как чистая, так и зашумленная (пыль, грязь, различные артефакты вызванные деформацией номерной пластины, тенями, неравномерной освещенностью). Размер картинки с символом примерно 20Х20 пикселей.Как мне определиться с выбором метода, пожалуйста, посоветуйте.
-
Здравствуйте, у меня такая ситуация - web сервер RaspberryPI из пакета RPi_Cam_Web_Interface выдает мне непрерывно меняющиеся картинки на адрес вида http://<ipaddr>/html/cam_pic.php? в браузере эта картинка видна, обновляется по F5. Пытаюсь получить ее с пом. cv2.imread() в opencv - выдает ошибку
warning: Error opening file (../../modules/highgui/src/cap_ffmpeg_impl.hpp:545)
файл при этом на месте.
Картинки из jpg файлов открываю нормально, ffmpeg установлен. Видеопотоки h264 и MJPEG из файлов открываю, также открываю поток сгенерированный с помощью Raspivid (h264)
поток этот получаю с адреса http://<ipaddr>:8160 -путем cap = cv2.VideoCapture('http://<ipaddr>:8160')
c задержкой в 40 сек, но получаю.
встречал рекомендации удалить все opencv_** **.dll из C:/Windows/System32 - у меня там нет таких dll.
переключение в web-сервере RaspberryPi с передачи последовательности картинок на MJPEG ( с переходом, соответственно, от imread к VideoCapture) ничего не изменило
Что это может быть? Как мне эту картинку вытащить?
Спасибо.
-
mrgloom, правильно я понял Вашу мысль, что если есть TBB, то OpenMP задействовано не будет? Что Вы имеете ввиду "cv::parallel_for может иметь несколько "бэкэндов" ? в файле по ссылке упоминаний про IPP я не нашел...
-
Да
-
Включаю\отключаю использование OpenMP и TBB. Включаю/отключаю именно их вместе, т.к. они оба включены в сборке. вне зависимости от того, включены они или нет, вижу от 5 до 12 потоков своего приложения. они в совокупности грузят все 4 ядра. совокупная загрузка цп - 38 - 40%. включаю использование OpenMP добавляя #include <omp.h> и #pragma omp parallel for перед процедурами, которые, как мне кажется, можно распараллелить.
никаких изменений по сравнению с вариантом когда я не использую OpenMP я не вижу. что так ,что эдак, время цикла на CoreI7 с 4 ядрами колеблется от 50 до 60 мс. Можно-ли выжать что-то еще из моего железа, до того как перейти на GPU ?

непонятный артефакт на снимке
в Обсуждение общих вопросов
Опубликовано · Report reply