
prim.ko
-
Количество публикаций
42 -
Зарегистрирован
-
Посещение
-
Days Won
2
Сообщения, опубликованные пользователем prim.ko
-
-
2 часа назад, Nuzhny сказал:При помощи чего?
Семантическая сегментация на U-Net. Дальше использовал непараметрическое восстановление плотности, используя центры масс зданий. Затем матрица "плотностей" использовалась в монте-карло. С учетом известной точки старта полета по GPS или по ручному вводу выходит вполне сносно. Подключаем еще на сегментации класс дороги, деревья и вероятности "гуляют" еще меньше.
-
 1
1
-
-
Проблема давно решена при помощи семантической+Монте карло
-
16 часов назад, mrgloom сказал:Как насчёт того чтобы натренировать siamese network для определения меры похожести тайлов?
Как выглядит реализация этого решения? Это будет как на imagenet`e?
-
34 минуты назад, Nuzhny сказал:Меня всё таки не покидает мысль о ключевых точках. Найти их на карте, хранить. Они же содержат в себе и масштаб также, часто точка+дескриптор - описывают целое озеро. Или вообще что-то типа MODS посмотре
Получается при сравнении дескрипторов будем будем пользоваться обычнмы матчером?
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True) matches = bf.match(des1,des2) matches = sorted(matches, key = lambda x:x.distance)
-
Проблема тут скорей в том, что гораздо большую ценность имеет факт наличия объекта определенного класса, чем его форма ( для вычисления моментов ). Я думаю, что необходимо как-то перейти к относительной мере сходства между объектами. В качестве свойств объектов например вычислять центр масс объекта и использовать координаты центра масс на векторной глобальной карте и сегментированной картинке, и каким-то образом плясать от этого. Плюсом возможно станет избавление от слоев пирамиды.
Куда смотреть?
На пальцах: увидели объект А класса дом, увидели объект Б класса дом, рассчитали центр масс, сравнили расстояние. ищем что-то похожее в базе
-
В 26.06.2017 at 17:47, Nuzhny сказал:Фазовая корреляция - это хорошо. Ещё как вариант можно брать то, что Szeliski называет Parametric motion в своей книге.
В общем Inverse compositial - это тоже хорошо, но он бесполезен в условиях сегментации. Наличие общих черт между предыдущим и текущим сегментированным кадром крайне невелико. При сравнении моментов между сегментированным изображением и векторной картой ничего толкового не выходит
-
2 часа назад, Nuzhny сказал:получатся ближе к истине: х = 62, у = 70.
Почему-то у меня выходит
x= 47.7060367454
y = 60.4724409449import numpy as np def calc(tiles_arr, weights, tr): res = 0 weights = np.delete (weights, np.where (weights > tr)) for i in range (len(weights)): res += tiles_arr[i]*(1-weights[i]/(np.sum(weights))) return res / len(weights) weights=np.array([0.0017, 0.0028, 0.00185, 0.00427]) x = [0,256,0,256] y = [0,0,256,256] print (calc(x, weights, 0.004)) print(calc(y, weights, 0.004))
-
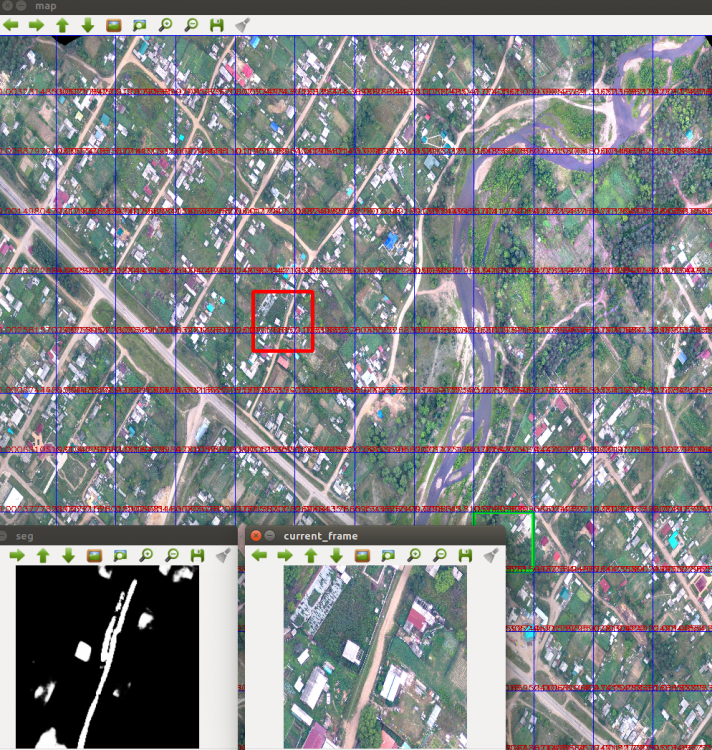
8 минут назад, Nuzhny сказал:А где там находится истинное положение объекта?
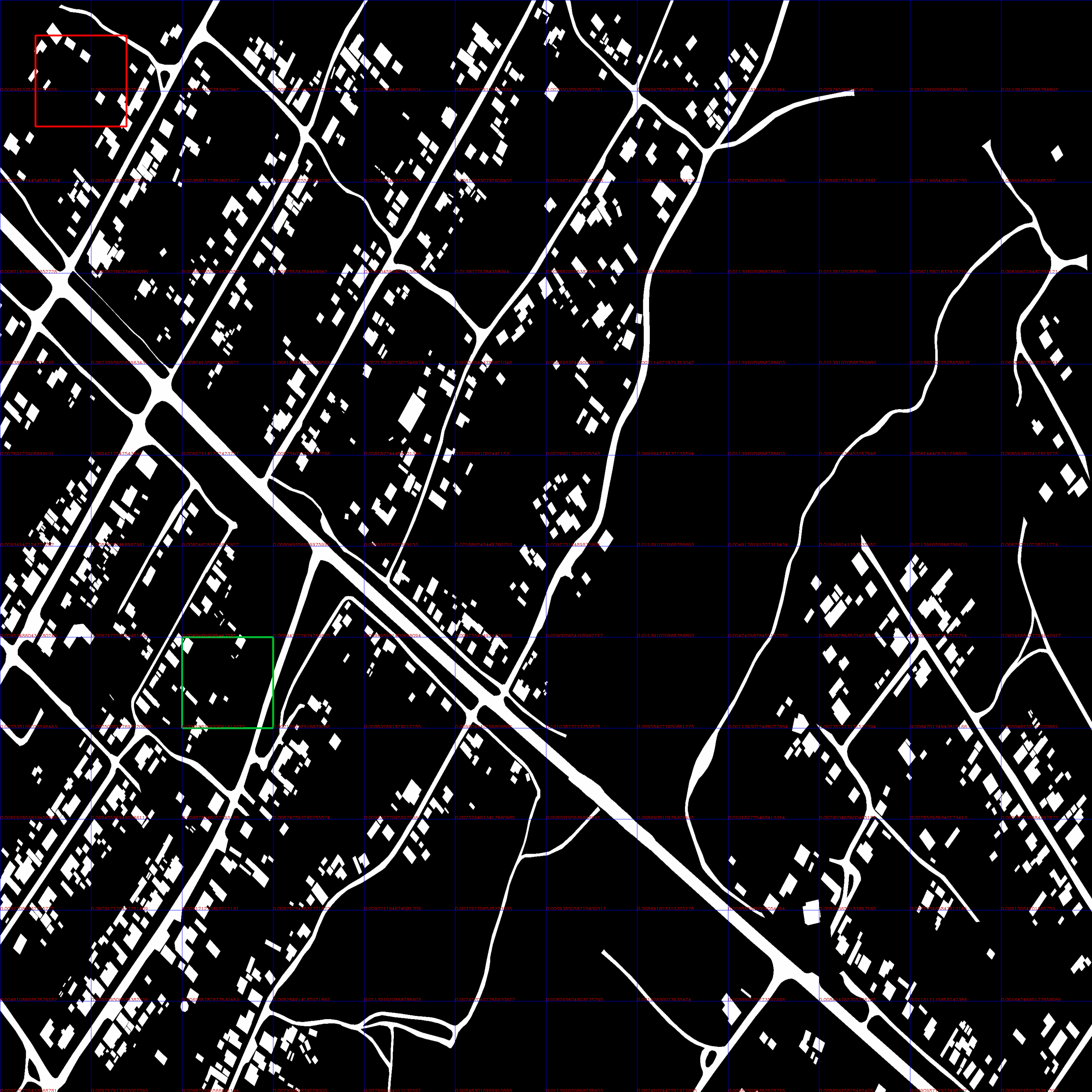
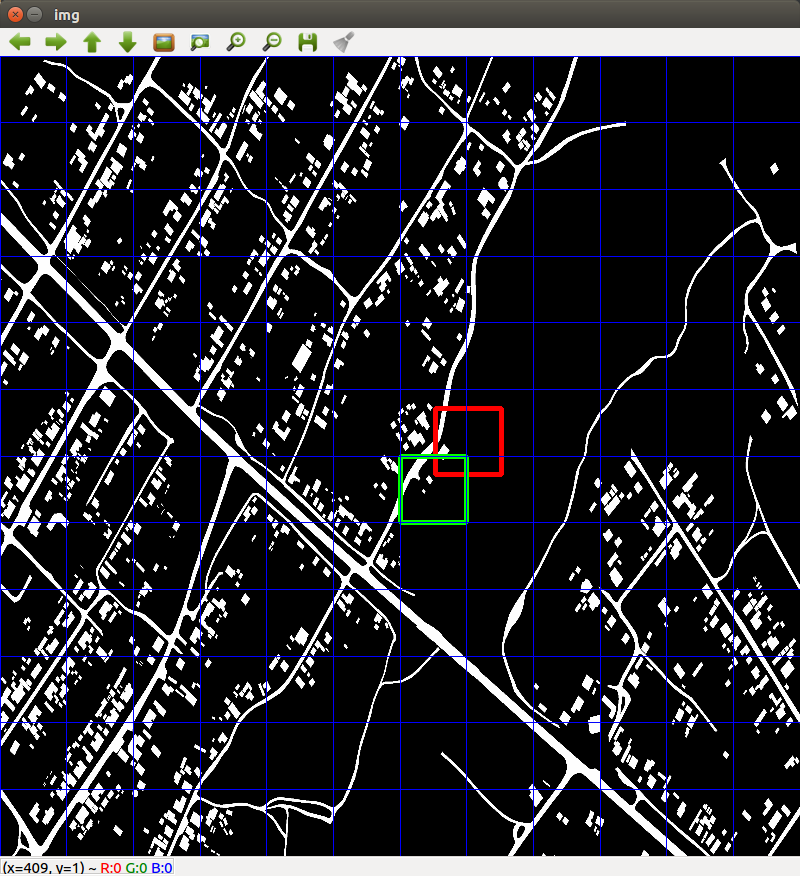
Истинное положение объекта обведено красной рамкой, вычисленное моментами - зеленой рамкой (без всяких улучшений тупым сравниванием ).
Поэтому на первой итерации зеленая рамка перекрывает красную - метрика = 0,0
-
1 час назад, Nuzhny сказал:Я ожидал увидеть значения метрики в каждом из тайлов. Найти минимум, значения метрики в тайлах рядом. Если они совсем большие, то не учитывать. С остальными взвешивать.
Например, минимальная метрика равна n1 = 0.001, у соседа справа n2 = 0.002. У остальных соседей больше 0.1, т.е. больше некоторого порога, всех их не учитываем.
Тогда получим координаты:
x = x1 * (1 - n1 / (n1 + n2)) + x2 * (1 - n2 / (n1 + n2))
y = y1 * (1 - n1 / (n1 + n2)) + y2 * (1 - n2 / (n1 + n2))
Как-то так.
В скринах выводится метрика в каждом из тайлов ( сравнивается с текущим кадром ).
Сейчас остановился на фазовой корреляции. Она дает отличные результаты в качестве "уточнения" области поиска абсолютных координат объекта.2 часа назад, mrgloom сказал:А из чего это следует |log2(max(max(H,W), 256)/256|+1 ?
Похоже что в таком идеальном случае можно сравнивать через template matching или chamfer matching.
На кагле кстати была задача по сегментации спутниковых фотоснимков https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection
p.s. задача интересная, держите нас в курсе.
Если я не ошибаюсь, так работают всякие SASplanet и др. гис системы, при отображении глобальной карты на заданный масштаб. В ods dstl уже спрашивал совета. Оттуда и перенял опыт тренировки UNet и использования ее для данной задачи.
-
18 часов назад, Nuzhny сказал:Да, именно это. Можно попробовать за положение тайла брать взвешенное значение окрестных к максимуму тайлов. Веса - как раз твоя метрика.
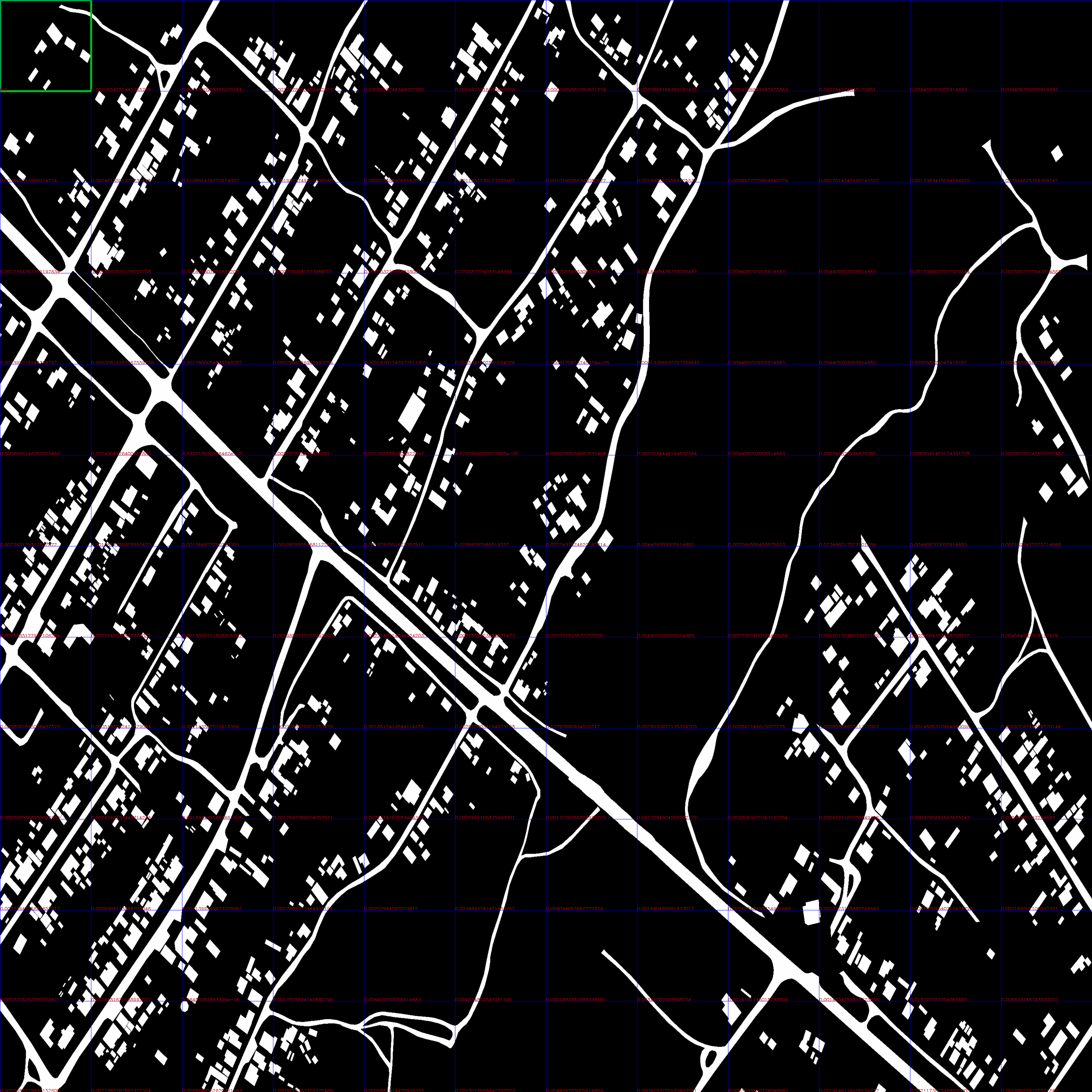
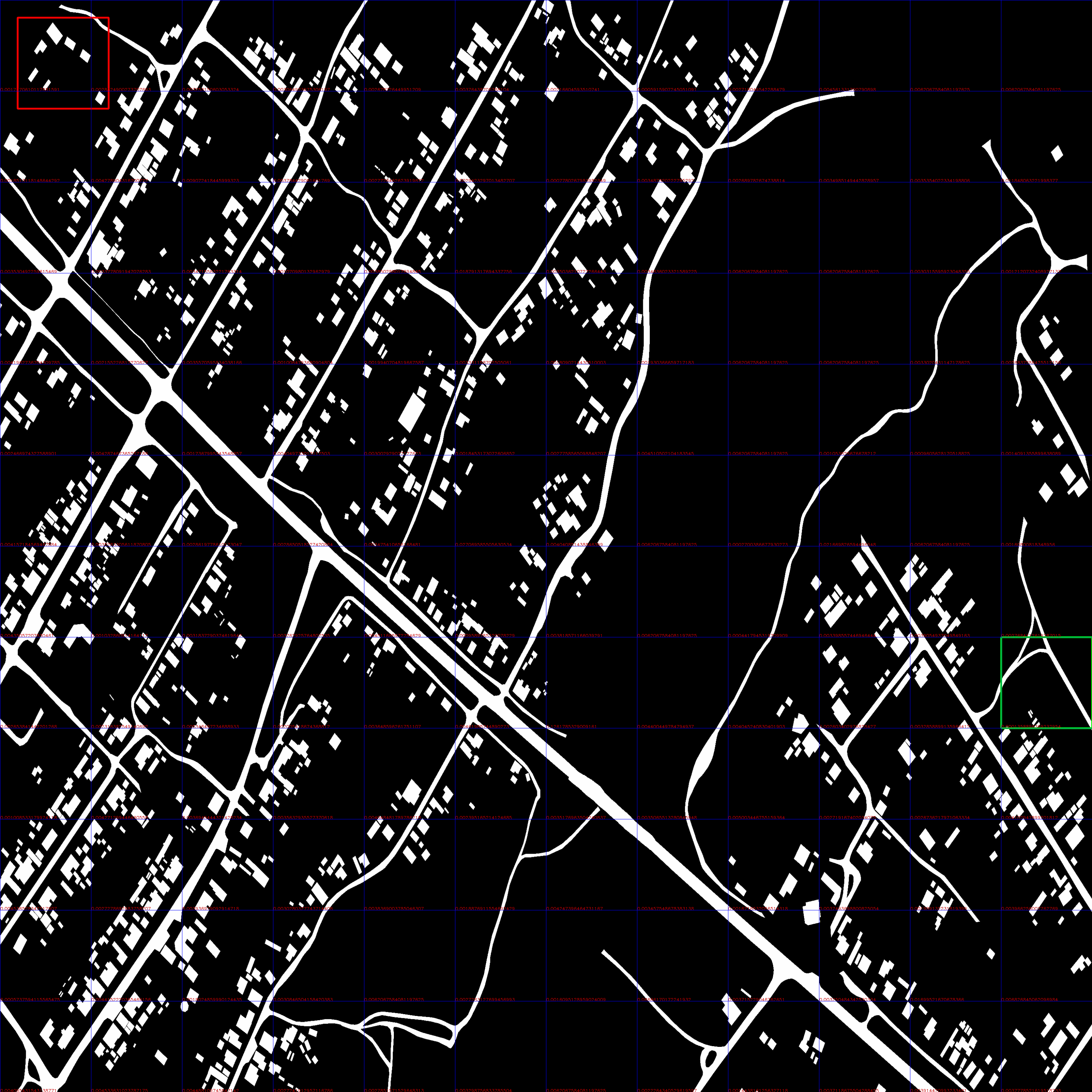
Криво, но сделал в большом разрешении.
Взято три итерации. На каждой итерации красное окно сдвигалось на 50 pix.
#1 current min distance: 0.0 #2 current min distance: 0.0001358896369232954 #3 current min distance: 0.00016839950091911252
Взвешивать средним?
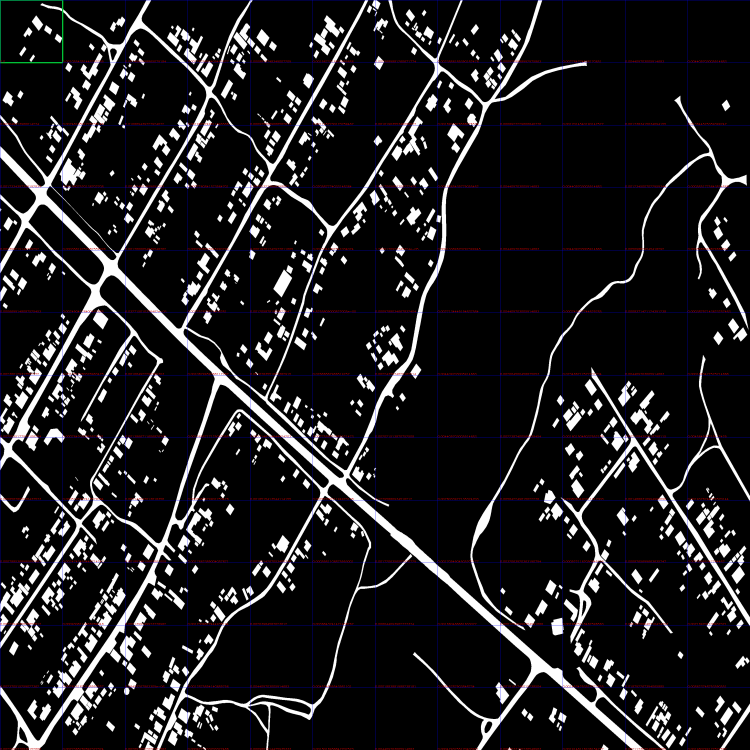
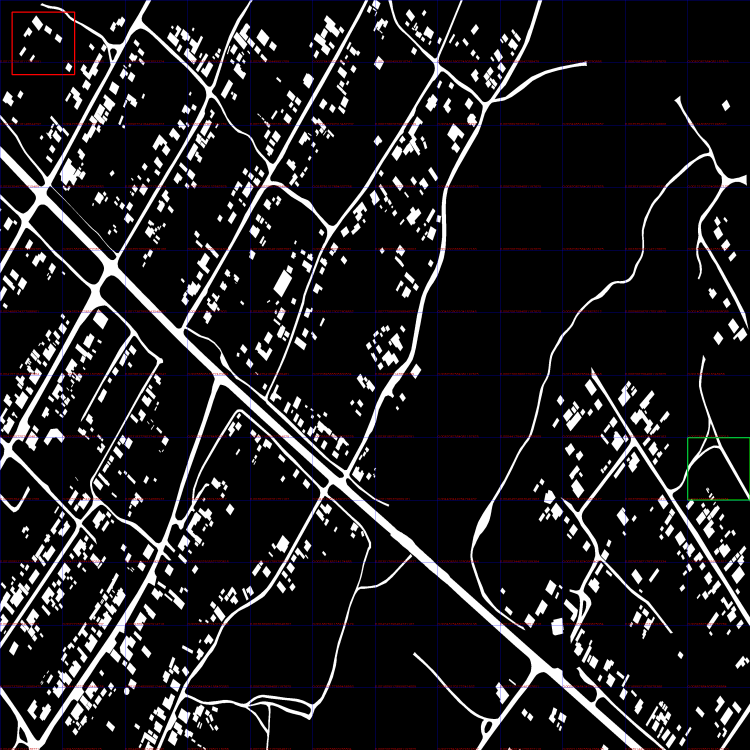
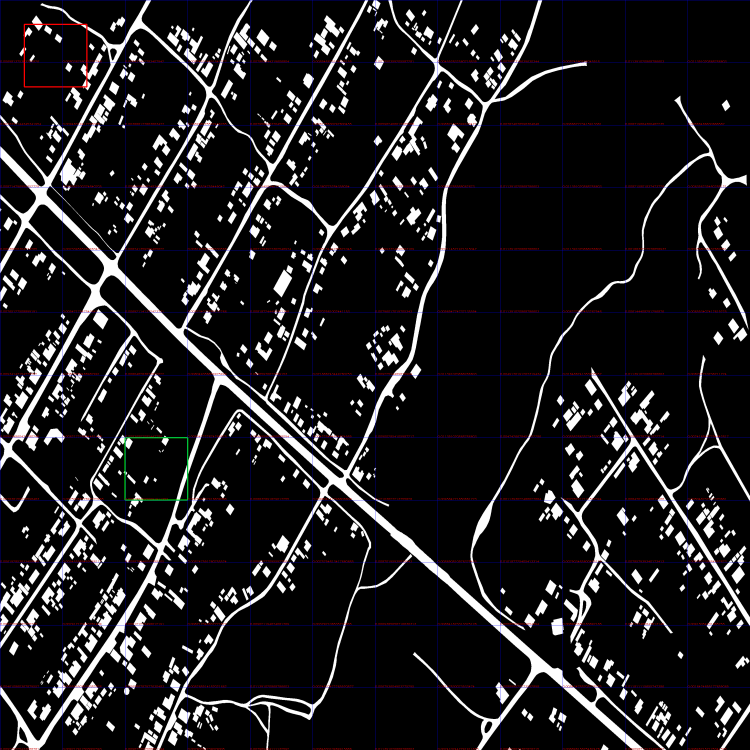
-
Да, если ты имеешь ввиду значения между текущим кадром с бла и всеми тайлами векторной карты. Как это поможет?
-
Вечер добрый.
Хочу поделится тем, что у меня не получается в данной задаче.
Рассмотрим идеальный случай, когда нейросеть сегментирует землю идеально, и возможно использовать векторную карту для вычисления абсолютных координат бла.
Выполняю я следующее:В качестве подложки использую векторную карту местности. Векторную карту я разбиваю на тайлы 256*256 объединяя их в слои пирамиды, в которой кол-во слоев высчитываю как |log2(max(max(H,W), 256)/256|+1
H,W у меня размеры векторной карты.
Далее я вычисляю для каждого тайла каждого уровня hu moments, сохраняю информацию на диск.Обучил нейронку на спутниковых снимках, скармливаю ей изображения с бла.
hu moments сегментированного изображения сравниваю с каждым тайлом выбранного слоя в пирамиде, используя евклидову метрику. Слой в пирамиде выбираю основываясь на высоте бла
Все хорошо, если изображение с бла совпадает с фрагментом из векторной карты, но когда изображение с бла "пересекает" несколько фрагментов из векторной карты, ничего хорошего не получается. Какие есть мысли по поводу всего этого? Как это победить?
На примере красным - положение бла, зеленым - вычисленная позиция.
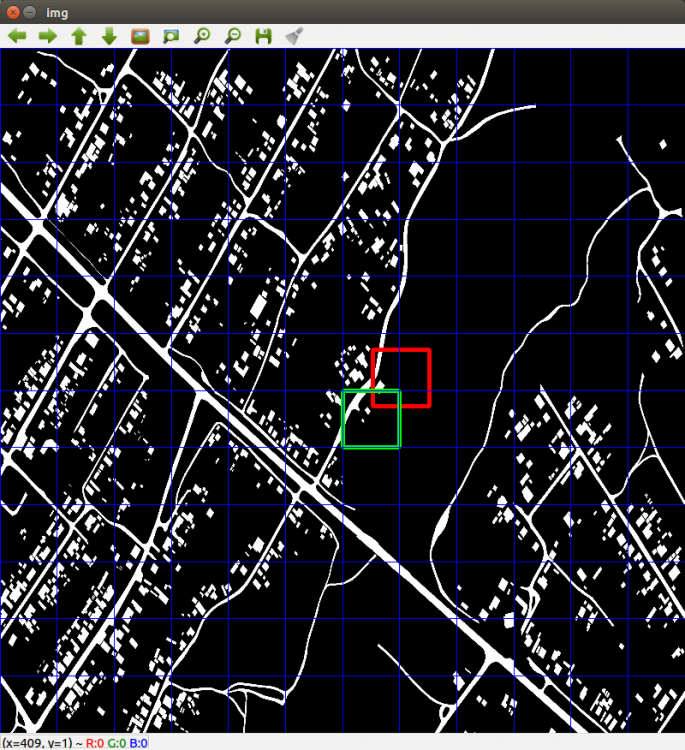
-
1
-
-
Приветствую.
Начал разбираться с сеткой UNet. Нашел реализацию на Keras + Theano, которой на кагле сегментировали нервы. В конкурсе изображения имели бинарные маски. А как подготавливать и скармливать сетке маски, если имеем несколько классов? Есть примеры кода?
И как создавать такие маски? Это будут просто заранее заданные цвета, или лучше перевести в градации серого с одним каналом?
Вот пример реализации UNet, где мужик подготавливает данные в *npy
from __future__ import print_function import os from skimage.transform import resize from skimage.io import imsave import numpy as np from keras.models import Model from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, UpSampling2D from keras.optimizers import Adam from keras.callbacks import ModelCheckpoint from keras import backend as K from data import load_train_data, load_test_data #prepare train data def create_train_data(): train_data_path = os.path.join(data_path, 'train') images = os.listdir(train_data_path) total = len(images) / 2 # учитываем маски и тренировочные imgs = np.ndarray((total, image_rows, image_cols), dtype=np.uint8) imgs_mask = np.ndarray((total, image_rows, image_cols), dtype=np.uint8) i = 0 print('-'*30) print('Creating training images...') print('-'*30) for image_name in images: if 'mask' in image_name: continue image_mask_name = image_name.split('.')[0] + '_mask.tif' img = imread(os.path.join(train_data_path, image_name), as_grey=True) img_mask = imread(os.path.join(train_data_path, image_mask_name), as_grey=True) img = np.array([img]) img_mask = np.array([img_mask]) imgs[i] = img imgs_mask[i] = img_mask if i % 100 == 0: print('Done: {0}/{1} images'.format(i, total)) i += 1 print('Loading done.') np.save('imgs_train.npy', imgs) np.save('imgs_mask_train.npy', imgs_mask) print('Saving to .npy files done.') from __future__ import print_function img_rows = 96 img_cols = 96 smooth = 1. def dice_coef(y_true, y_pred): y_true_f = K.flatten(y_true) y_pred_f = K.flatten(y_pred) intersection = K.sum(y_true_f * y_pred_f) return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth) def dice_coef_loss(y_true, y_pred): return -dice_coef(y_true, y_pred) def get_unet(): inputs = Input((img_rows, img_cols, 1)) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(inputs) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1) conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2) conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3) pool3 = MaxPooling2D(pool_size=(2, 2))(conv3) conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool3) conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4) pool4 = MaxPooling2D(pool_size=(2, 2))(conv4) conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(pool4) conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5) up6 = concatenate([UpSampling2D(size=(2, 2))(conv5), conv4], axis=3) conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6) conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6) up7 = concatenate([UpSampling2D(size=(2, 2))(conv6), conv3], axis=3) conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7) conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7) up8 = concatenate([UpSampling2D(size=(2, 2))(conv7), conv2], axis=3) conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8) conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8) up9 = concatenate([UpSampling2D(size=(2, 2))(conv8), conv1], axis=3) conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9) conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9) conv10 = Conv2D(1, (1, 1), activation='sigmoid')(conv9) model = Model(inputs=[inputs], outputs=[conv10]) model.compile(optimizer=Adam(lr=1e-5), loss=dice_coef_loss, metrics=[dice_coef]) return model def preprocess(imgs): imgs_p = np.ndarray((imgs.shape[0], img_rows, img_cols), dtype=np.uint8) for i in range(imgs.shape[0]): imgs_p[i] = resize(imgs[i], (img_cols, img_rows), preserve_range=True) imgs_p = imgs_p[..., np.newaxis] return imgs_p def train_and_predict(): print('-'*30) print('Loading and preprocessing train data...') print('-'*30) imgs_train, imgs_mask_train = load_train_data() imgs_train = preprocess(imgs_train) imgs_mask_train = preprocess(imgs_mask_train) imgs_train = imgs_train.astype('float32') mean = np.mean(imgs_train) # mean for data centering std = np.std(imgs_train) # std for data normalization imgs_train -= mean imgs_train /= std imgs_mask_train = imgs_mask_train.astype('float32') imgs_mask_train /= 255. # scale masks to [0, 1] print('-'*30) print('Creating and compiling model...') print('-'*30) model = get_unet() model_checkpoint = ModelCheckpoint('weights.h5', monitor='val_loss', save_best_only=True) print('-'*30) print('Fitting model...') print('-'*30) model.fit(imgs_train, imgs_mask_train, batch_size=32, nb_epoch=20, verbose=1, shuffle=True, validation_split=0.2, callbacks=[model_checkpoint]) print('-'*30) print('Loading and preprocessing test data...') print('-'*30) imgs_test, imgs_id_test = load_test_data() imgs_test = preprocess(imgs_test) imgs_test = imgs_test.astype('float32') imgs_test -= mean imgs_test /= std print('-'*30) print('Loading saved weights...') print('-'*30) model.load_weights('weights.h5') print('-'*30) print('Predicting masks on test data...') print('-'*30) imgs_mask_test = model.predict(imgs_test, verbose=1) np.save('imgs_mask_test.npy', imgs_mask_test) print('-' * 30) print('Saving predicted masks to files...') print('-' * 30) pred_dir = 'preds' if not os.path.exists(pred_dir): os.mkdir(pred_dir) for image, image_id in zip(imgs_mask_test, imgs_id_test): image = (image[:, :, 0] * 255.).astype(np.uint8) imsave(os.path.join(pred_dir, str(image_id) + '_pred.png'), image) if __name__ == '__main__': train_and_predict()
-
В 17.04.2017 at 15:27, mrgloom сказал:Задача не ясна. Пары изображений заданы заранее?
p.s. Есть такая штука
Задача первичная стоит не в сопоставлении фотоснимков, а в определении геопозиции объекта. Сопоставление пар кадров - это метод решения данной задачи, который первым пришел мне в голову. Какую информацию будем загружать в объект - здесь нет ограничений, пока не найдено оптимальное решение.
-
Применимость зимой я не рассматривал как раз из-за низкой корреляции.
6 часов назад, Nuzhny сказал:1. Точек может быть слишком мало. В этом случае надо использовать другой метод, те же контуры (если они есть).
В примере с контуром, который не замкнут как будет производиться сравнение? Ведь моменты дадут нам много совпадений.
Тут нейронка может дать существенный прирост информации для существующих/модифицированных алгоритмов?
-
Приветствую!
Думаю я обращусь по адресу со следующей задачей:
Необходимо вычислить позиционирование объекта по карте местности.
Объект производит снимки, камерой направленной вниз. Кадр из видеопотока можно обработать какой-нибудь нейронной сетью чтобы за что-нибудь зацепиться, и уже относительно классифицированного объекта плясать. Можно просто рассчитать перцептивный хэш изображения и сравнить с базой. Можно применить контурный анализ.
Попробовал реализацию хэшем:


Слева направо - изображение полученное объектом, изображение из Google maps
расстояние = 15


Слева направо - Google maps, Yandex maps
Расстояние = 7
Метод показывает вроде неплохие результаты. Если заранее загрузить спутниковую карту с максимальным уровнем тайлов, и перегнать каждый тайл в хэш, то получим быстрый результат при сравнении с таблицей хэшей. Вот только делается ли так?
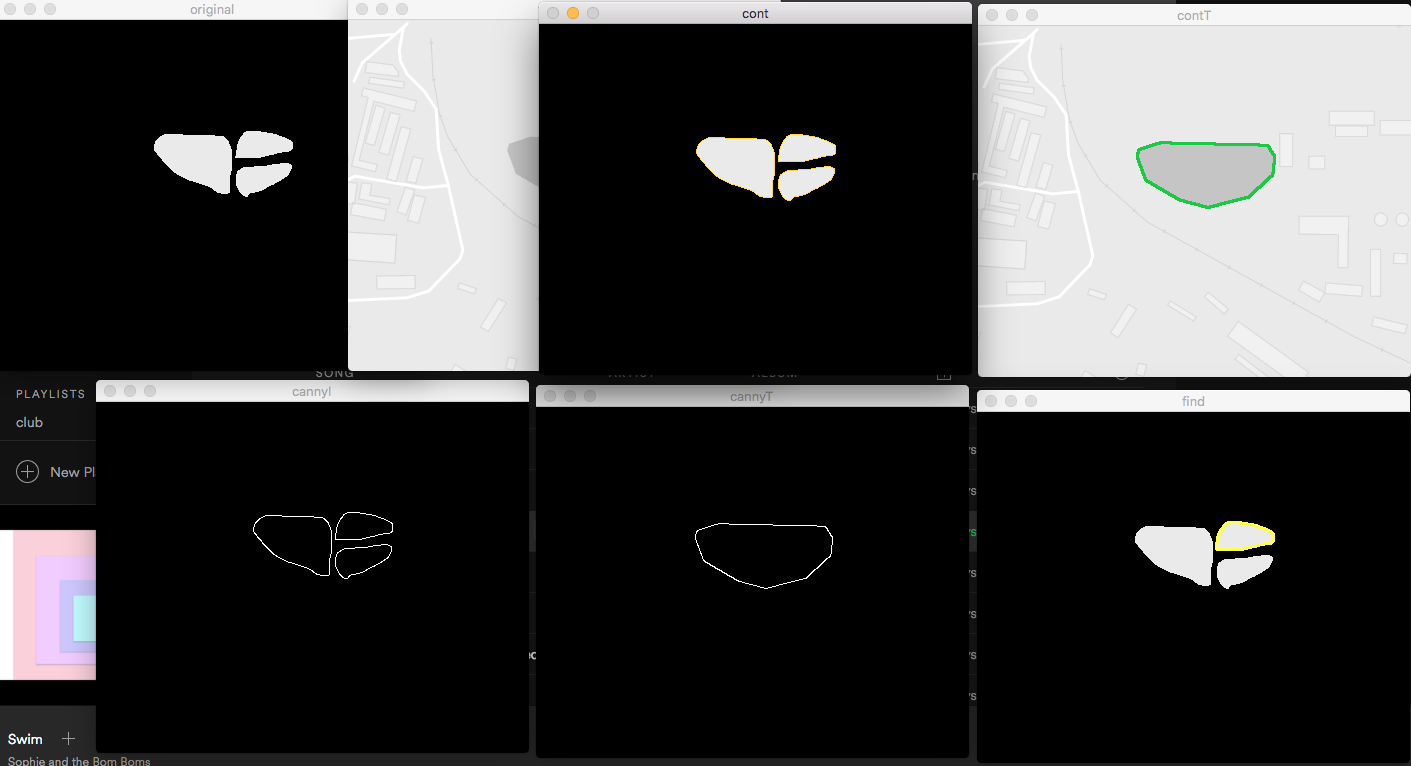
Второй вариант который я попробовал это контурный анализ при помощи Hu моментов:
Подал на вход сегментированное сетью изображение, в котором белым залит класс "вода". Затем подал векторную карту в качестве шаблона. Получилось не очень хорошо. Алгоритм выделил контур в самой нижней части изображения (окно find).

Если подать на вход маску а не изображение совмещенное с результатами сегментации, то вроде бы как алгоритм срабатывает:
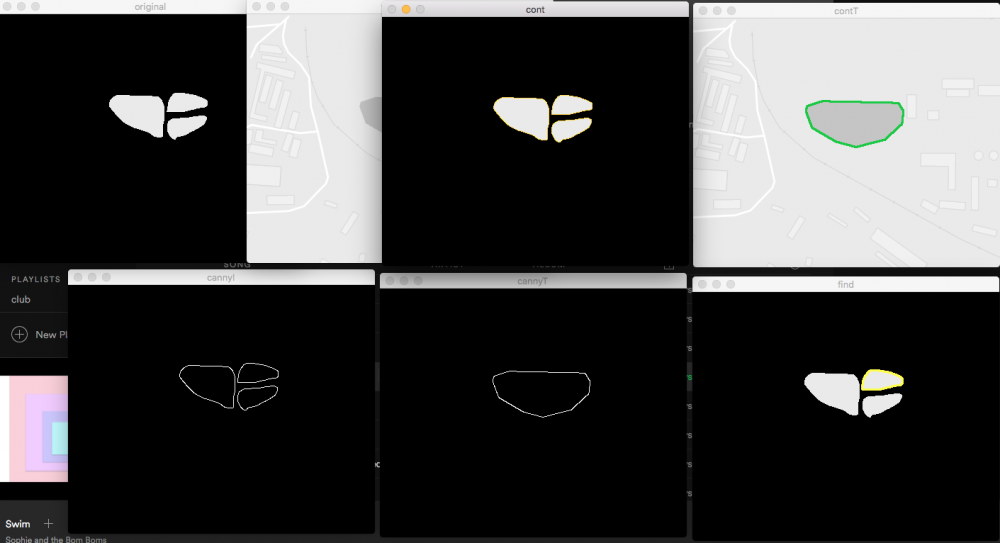
Немного не то нашел, ну да ладно. Близко.
Минус данного алгоритма в том, что если у меня будет множество шаблонов, скажем это будут все озера и реки в округе, и я стану сравнивать изображение на котором не полностью уместилось в кадр озеро или река, то ничего хорошего не выйдет из этого, так как контур не полностью замкнет водную поверхность. Что посоветуете в данной ситуации? Только не нужно вопросов про GPS, на то оно и тех. зрение, для того и спрашиваю совета на данном форуме.


Multi-class segmentation with a UNet
в Вопросы по нейросетям и ИИ
Опубликовано · Report reply
Ученые мужики, подскажите что почитать по проектированию сетей на Caffe. Дело в том, что пытаюсь переписать U-Net на Caffe. И описание моделей в prototxt это совсем не ванильный Keras. Многое, что в Keras остается "черным ящиком" теперь не дает мне построить сетку на Caffe. Например начал с первой группы слоев U-Net
(Картинка взята из dstl)
layer { name: "label" type: "Data" top: "label" include { phase: TRAIN } transform_param { mirror: true } data_param { batch_size: 5 backend: LMDB } } layer { name: "data" type: "Data" top: "data" include { phase: TEST } transform_param { mirror: true } data_param { batch_size: 5 backend: LMDB } } layer { name: "label" type: "Data" top: "label" include { phase: TEST } transform_param { mirror: true } data_param { batch_size: 5 backend: LMDB } } # data layers layer { name: "data" type: "Data" top: "data" include { phase: TRAIN } transform_param { mirror: true } data_param { batch_size: 5 backend: LMDB } } #-------------layer group 1--------------- layer { name: "conv1a" type: "Convolution" bottom: "data" top: "conv1a" convolution_param { num_output: 32 kernel_size: 3 pad: 1 stride: 1 engine: CUDNN weight_filler { type: "xavier" #std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "conv1a_BN" type: "BatchNorm" bottom: "conv1a" top: "conv1a_BN" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } batch_norm_param { use_global_stats: false moving_average_fraction: 0.95 } } layer { name: "elu1" type: "ELU" elu_param { alpha: 1.0} bottom: "conv1a_BN" top: "conv1a_BN" } layer { name: "conv1b" type: "Convolution" bottom: "conv1a_BN" top: "conv1b" convolution_param { num_output: 32 kernel_size: 3 pad: 1 stride: 1 engine: CUDNN weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "conv1b_BN" type: "BatchNorm" bottom: "conv1b" top: "conv1b_BN" param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } param { lr_mult: 0 decay_mult: 0 } batch_norm_param { use_global_stats: false moving_average_fraction: 0.95 } } layer { name: "elu2" type: "ELU" elu_param { alpha: 1.0} bottom: "conv1b_BN" top: "conv1b_BN" } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "conv1b_BN" bottom: "label" top: "loss" include: { phase: TRAIN } }После загрузки данной сетки в DIGITS - тишина. В качестве обучения использую разметку дорог toronto dataset https://www.cs.toronto.edu/~vmnih/data/ . Там бинарная разметка.
В DIGITS подготовил датасет для сегментации. Интерполировал его к разрешению 500*500 и указал "color map specification" from text file. В нем указал
В общем не понятно, почему не шевелится DIGITS?