
idrua
-
Количество публикаций
63 -
Зарегистрирован
-
Посещение
-
Days Won
3
Сообщения, опубликованные пользователем idrua
-
-
OpenCV в данном случаи не поможет. Нейросетями можно попробовать, при условии, что датасет с картинками присутствует. Задача бинарной классификации. Мало чем отличается от разделения кошек и собак на фото.
P.S. Но если все картинки в таком качестве, то не уверен. На вашем фото есть пассажир или нет? Я, например, не вижу никаких пассажиров.
-
Недавно где-то читал, что на UNet очень плохо заходит multi-class (плюс дисбаланс классов). Лучше использовать UNet только для бинарной.
-
У меня всё получилось! Почти год прошел. Что я только не пробовал, к кому только не обращался за помощью...а в итоге сделал сам.
-
 1
1
-
-
23 часа назад, ColaClassic сказал:Я прям завидую вашим познаниям в ML
 Обладая такими же знаниями, я бы, наверное, за пару дней написал прогу требуемую
Обладая такими же знаниями, я бы, наверное, за пару дней написал прогу требуемую
Это зря, завидовать тут нечему. Я, например, одну из своих задач уже как год решаю, и всё безуспешно. Сперва пробовал пакетом OpenCV, потом ML(классификаторы разные) + OpenCV. И только теперь DL.
Ну и есть четкое деление ML и CV. Это две разные области наук. Они конечно частично пересекаются, но крайне незначительно. CV нужна для поиска признаков (сегменты, цвета сегментов, линии, да всё что угодно). В ML по этим признакам можно обучить модель, которая и будет "искать" трещины и царапины. Есть еще DL, но там вообще всё сложно. За пару дней вашу задачу вряд ли кто решит. За месяц, имея большой датасет с картинками, может быть.
Если хотите решать самостоятельно, то это очень надолго. Изучить Python, пройти пару курсов по ML, посмотреть примеры работ по CV. А если не взлетит, то смотреть в сторону DL. Как-то так... Естественно, ИМХО. Возможно у знатоков будет другое мнение.-
1
-
-
9 часов назад, ColaClassic сказал:idrua, меня заинтересовал ваш второй способ) Попробую изучить данный фильтр. Надо глянуть реализован ли он на OpenCV, что-то не встречал такой.
Реализован. Но это не панацея. Фильтрами можно будет уловить большие трещины под углами (это быстро, просто и мало кода). С пятнами уже тяжелее будет. И совсем невозможно будет уловить отбитые куски на краях плитки. Поэтому просто фильтров недостаточно. Действительно, одним из простых способов решения подобных задач является создание классификатора. Но, как мне кажется, с подобными терминами вы еще не знакомы. Только на обучение ML в среднем уходит от 3 месяцев. Плюс поиск признаков для классификатора: цвет, тон, насыщенность, а может средний тон сегмента, а может кластеризацией можно что-то сегментировать и т.д. В общем, это всё выльется в месяцы работы, если самому впервые разбираться (это я по своему горькому опыту). И самое печальное здесь, не факт, что заработает на должном уровне. Такой он, machine learning. Это своего рода искусство.
-
1
-
-
3 часа назад, mrgloom сказал:Главная сложность(зависит от фото) это детектирование ректа плитки, потом разворот, кроп.
Кстати, а зачем? Нейросетка и так съесть картинку без всех этих телодвижений. См. пример U-Net сетей. Например Carvana на Kaggle. Другое дело с разметкой -- это на месяцы
")
-
1 час назад, Nuzhny сказал:Правильней заполнять не средним, а медианой. Например, есть чёрный и белый цвет. Заполнить средним - серым будет совсем не правильно, а медианой (какого цвета больше) точнее.
Согласен, если выборка упорядочена по значениям и их немного. А если нет?
Для выборки 3, 5, 5, 27, 114, 115, 1037 медиана будет числом 5. Если вместо пустоты заполнять 5, то результат будет не очень. Вот поэтому иногда и смотрят на другие фичи. Определяют ближайшего соседа по ним (кластеризацией или классификацией) и берут пустые данные из соседей. -
Нужен именно алгоритм? Вообще, это один из популярных классификаторов в области ML (обучение с учителем). И с ним можно решать абсолютно любые задачи классификации/регресии. От сортов ириса до более сложных (прогнозирование курса биткоинта ).
Для чего нужен? Лично я его использую в двух случаях.
При построение ансамблей моделей. Это когда есть до десятка простых моделей (knn — это простая модель, если что) и все они имеют низкую точность прогнозирования. А все вместе они существенно повышают качество прогнозирования. Т.е. если из 10 простых моделей 7 моделей голосуют за класс1, то это действительно класс1. Что-то типа мудрости толпы.
Для заполнения пропущенных значений. Предположим есть датасет с пропусками (часть данных не указана). Можно заполнить средними значениями, что иногда не совсем правильно. А можно заполнить очень близкими значениями из соседей. Т.е. ищем ближайшего соседа на основании тех данных что есть. Как нашли заполняем пропуски данными из ближайшего соседа.
-
Нейросеткой можно найти 99% всех дефектов. Но это не самый простой способ. Это самый сложный и самый точный. Размечать датасет нужно будет ручками, а это долго и сложно.
Самый простой способ — фильтрами Габора (возможно в замесе с чем-то еще). После применения фильтра появятся нехарактерные для плитки линии под углами. Точность будет гораздо ниже по сравнению с сеткой, но выше 90% (естественно, ИМХО).
Может быть кластеризация по цвету что-то даст. Или тот же FloodFill с параметрами закраски(чтобы он закрашивал только очень близкие по цвету сегменты). Или watershed. Но сложно что-то предположить не видя картинок. Надо пробовать разные варианты.
-
1
-
-
Нужно именно нейросетью? Дело в том, что простые геометрические фигуры можно и без нейросетей успешно детектировать.
-
Есть ли смысл? Нейронные сети постепенно вытесняют решения из библиотек компьютерного зрения.
Вот, например, вчерашняя статья С.Николенко про сегментацию: https://medium.com/neuromation-io-blog/neuronuggets-segmentation-with-mask-r-cnn-c76d363b67fb
Сейчас актуальнее машинное обучение.
-
Я пробовал. Нормально распознает, если нормально обучить. БОльшая точность при распознавании отдельных слов или букв, по сравнению со строками текста или предложениями. Отдельная проблема с сегментированием. Иногда контур (Rect) буквы/цифры берется неправильно и нужно исправлять. Т.е. объединить близко расположенные "коробки", понять истинный размер символа и распознать одиночный символ.
P.S. Но обучать tesseract очень непростая задача. -
8 минут назад, pasutka сказал:А по распознаванию номеров жд вагонов есть тема? что то не нашёл отдельную ветку.
Может кто то уже реализовывал такие задачи?
Вопрос возможности реализации на Delphi XE... возможно ли подклчить нужные бибилиотеки ?
Использование нейросетей для меня в новинку, думаю с чего начать.
Может у кого есть обученная сеть или дата файлы для обучения?
p.s.: Возможно кто то захочет помочь в разработке (консультант или разработчик) за вознагрождение
Там печатные цифры, а не рукописные. Любой движок должен справляться, даже из бесплатных. В конце-концов можно немного дообучить тот же tesseract, чтобы достигать еще большей точности. Я не уверен на счет Delphi, как-то совсем мало проектов (примеров) на нем в области CV, ML, AI. Но что мешает создать библиотеку на том же C#(C++) и вызывать методы из Delphi?
Думаю, что бОльшей проблемой будет не распознавание, а поиск нужной зоны на фото и его последующая бинаризация (пересветы, блики).
-
У меня была почти такая же задача, только продолжить нужно было не контур, а печатные линии. Разрешил при помощи Хафа, где одним из параметров выступает maxLineGrap ( максимальный разрыв между двумя точками, которые должны рассматриваться в одной линии).

RANSAC еще можно использовать. http://www.imagexd.org/tutorial/lessons/1_ransac.html
-
В OpenCV это одна строка кода.
Cv2.CvtColor(img, img, ColorConversionCodes.BGR2YUV);Ну и в той же вики есть формула перевода.
-
ConnectedComponents в принципе неплохо отрабатывает и можно улучшать (добиваясь улучшить контур клетки с помощью RANSAC или HoughCircles ). Картинку не могу загрузить на сайт, чтобы показать результат.
А вообще надо пробовать Superpixels. Там еще будет лучше и в разы.
-
Добрый день.
connectedComponents прекрасно работает для бинарного изображения, но хотелось бы и для цветного.
Реализовал через заливку (FloodFill), но есть нюансы:1) если делать большие шаги Scalar.All(50), то закрашивает не совсем правильно. Закрашивает то, что различимо по цвету.
2)если делать мелкие шаги Scalar.All(20), то слишком много областей ( labels) получается.
В общем, через заливку не получается найти золотую середину. Может кто-то встречал аналоги?
Спасибо.
-
Одной фотографии абитуриента будет явно недостаточно для такой задачи.
Кто такие "каскадеры"?
-
Да, по этой. Вот уже 3 месяц пошел. Всё никак...
-
Занятно. Давай я тебе свои картинки вышлю. Может чем-то сможешь помочь? Еще и заплачу серьезно.
-
Можно также поиграться с постеризацией (https://en.wikipedia.org/wiki/Posterization).
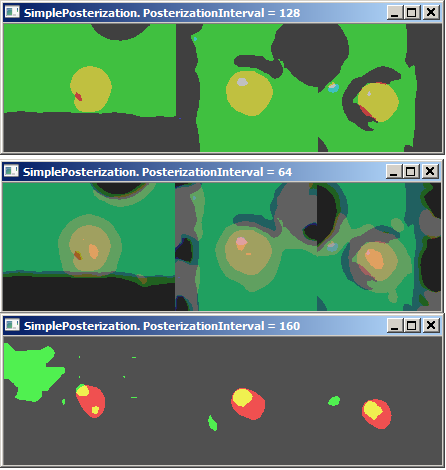
Постеризация в сером.

-
 1
1
-
-
Есть две мысли.
1) Можно кластеризовать изображение, а только потом искать круги
2) FloodFill, если почитать детальнее, может закрашивать не только определенный цвет, но и диапазон определенного цвета. Т.е. задаем базовый цвет и разницу от базового. В теории, должен выделить.
-
1
-
-
Accord.net может помочь в этом вопросе. Как раз на C#. И HOG, и куча классификаторов, и нейросети, и примеры. Было бы желание...
-
Картинку не мешало бы прикрепить. А вообще оператор Собеля отлично выделяет линии.
Услуга по распознаванию объекта
в OpenCV
Опубликовано · Report reply
И зачем мне это? Вы сами видите там пассажира? Если нет, то и нейросеть не увидит. Ну и датасет с картинками нужен. Где будут тысячи фотографий машин с пассажирами и без. Тогда можно будет решить с высокой точностью и эту задачу.