
idrua
-
Количество публикаций
63 -
Зарегистрирован
-
Посещение
-
Days Won
3
Сообщения, опубликованные пользователем idrua
-
-
5 часов назад, mrgloom сказал:Кстати говоря
Спасибо, посмотрю. Но там шум совсем другой: следы от стаканов, загнутые страницы и т.д. Это все гораздо проще удалить, имхо. У меня же на черном печатном пишут черным рукописным (синий тоже бывает, но с ним легче).
Наверное, следует написать пару слов о промежуточных результатах на сейчас. Во первых, спасибо, Nuzhny, что помогает советами и кодом вот уже месяц.
1. Разложить по цвету мои картинки невозможно. Что только не делали: добавляли LBP, оператор Собеля, различные маски. Все мимо. Ни кластеризация, ни классификация не справляются.
2. Решили добавить принадлежность пикселя с типу текста. Ведь что-то таки известно. Можно получить контуры и отобрать только те, которые подходят по размеру печатных букв. Определяются не все, иногда ложные появляются (с этим беда). А еще можно получить рукописный из LSD (длинные линии под углом 10..80 и 100..170) будут говорить о рукописном. В результате получается такая маска(см.ниже). Результаты пока не очень, но заметно лучше, чем просто по цвету с всевозможными "играми" из LBP, Sobel и т.д.В красном и зеленом результат разложения. Это мой первый опыт работы с классификатором. Думаю, что у Nuzhny получше выйдет, но он пока занят.

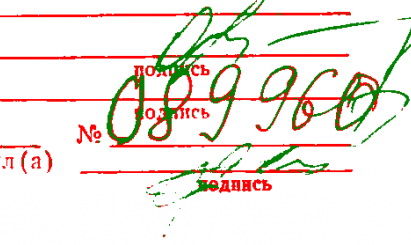

-
Установил C++, взял за основу код (Smorodov) с небольшими правками ( беру для обучения все не белое). Результат, не очень.
По первым двум каналам (H-S) совсем плохо. Чуть лучше по другим парам (H-V или S-V или полностью H-S-V). Иногда по RGB лучше раскладывает, чем по HSV.
Также не понятно, как программно контролировать устраивает результат или не устраивает.Ниже результаты. Оригинал, точки для обучения, результат разложения. На первой картинке по H-S. На второй по H-S-V.
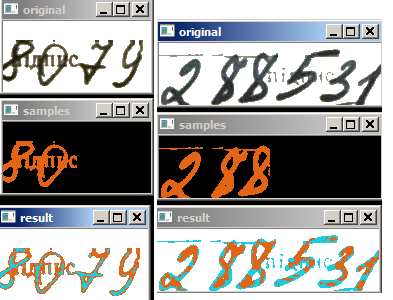
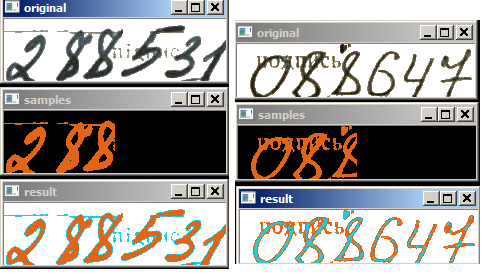
-
5 часов назад, Nuzhny сказал:2. Надо продолжать.
Продолжил... Должен сказать, что установка пакета OpenCV на С++ в корне отличается от C#. Скачал opencv-3.2.0-vc14.exe, распаковал, прописал все пути. Создал тестовый пример. Компилируется успешно. Но выяснилось, что это только для x64, а у меня x86. Насколько я понял, нужно при помощи CMAKE создавать нужные библиотеки из папки source.
P.S. В opencv-2.4.13.3-vc14.exe есть папка x86. Наверное, так проще будет. Особенно для меня )))
-
4 часа назад, Nuzhny сказал:1. Предлагаю забить на C# и проверить вообще будет ли подход работать, на С++, например. или на Питоне.
2. Да, я предлагаю именно два класса с разными чёрными. Фон вообще отсекать по порогу, чтобы он в EM не участвовал. Уверен, что оттенков фона может быть много и он попадёт не в одну, а в две модели.
3. Да, HSV очень удобен для таких задач. Лучше добавлять в качестве признаков и H, и S каналы.
1. Легко сказать, но трудно сделать. Не использовал до этого момента плюсы и Питон. Ладно, буду пробовать. Какой пакет Nuget устанавливать? Вижу два популярных от Itseez и shimat.
2. Удалил фон. Сделал его белым, чтобы удобнее отсекать.
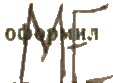
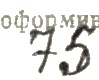
-
Вот, блин... ни одного примера на C# во всем интернете по Expectation Maximization. Могу я попросить exe'шник с dll'ками для тестов (для 86 машины)? Тем более, его ранее раздавали на форуме. Насколько я понимаю, мне нужно разложить на 3 канала (белый(фон), черный(печатный), черный (рукописный)). Не совсем понял, почему Nuzhny предлагает на 2. Или имелось 2 класса с разными черными?
P.S. Смотрел свои проблемные картинки в HSV. Hue для печатного и рукописного почти не отличается (если черным рукописным по черному печатному). А вот Saturation иногда отличается и очень сильно.
-
2 часа назад, Nuzhny сказал:Если цвет различается, то самое время для сегментации. Убери фон, чтобы не мешал, а оставшееся сегментируй с помощью EM на два класса. Только сегментируй не в RGB пространстве, а переведи в HSV и возьми либо значения первых двух каналов, либо просто цвет.
Спасибо тебе, добрый человек! Буду разбираться и проверять.
-
4 часа назад, Smorodov сказал:разлиновку можно убрать по гистограмме, если инвертировать изображение и найти суммы вдоль строк пикселей, это даст пики на местах линий. А вот выковыривать текст это задачка много сложнее. Можно попробовать нейронку натренироватьб если на вход подавать изображение с печатным текстом, а на выход очищенную надпись, то может и сработать, но нужно большой датасет руками делать, самому почистить штук 1000-2000 таких изображений.
Линии уже удалены. Я правда не гистограммой делал, а HoughLines. Принцип примерно такой же.
Нейронку пока не могу. Это долго и нет нужного объема изображений.
По теме чистки (очередная попытка):
1)Известна примерная зона рукописного текста.
2)Бинаризирую, провожу условно линию по высоте \ 2.
3)Ищу все точки черного цвета на условной линии.
4) Заливаю другим цветом (FloodFill) найденные точки.
Получается отсеять часть букв, которые не соприкасаются с рукописным. Но все равно плохо.

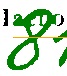
-
ЦитатаНе получается с наложением эталона. Слишком много эталонов (один и тот же текст, но разными шрифтами и размерами). Может еще идеи какие? По толщине пера? По цвету печатного текста? Фильтры? Нужно любой ценой избавиться от печатного текста.
Очень часто цвет печатного и рукописного отличается. Но не могу придумать как на этом "сыграть".
P.S. Могу примеры картинок прикрепить.
-
Статью на хабре видел. Там фон удачно чистится по причине разных цветов фона и цифр.
ЦитатаПоскольку изображение трёхцветное, порежем его на каналы, а затем выбросим все точки, которые ярче 116 по всем каналам.
А у меня все черное. И рукописные цифры и печатный текст.
-
Добрый день.
Подскажите, какие есть варианты для очистки изображения от "шума"? Под шумом подразумеваю печатный текст "пiдпис" и "№". Нюанс еще в том, что этот текст может быть напечатан разными шрифтами и разного размера. Пробовал удалить наложением эталона с логическим AND. Получается, но далеко не идеально. Возможно, есть другой вариант очистки?
P.S. Угловой перекос устранил, линии удалил. Вопрос исключительно по очистке от печатного текста.

Очистка изображения от печатного текста
в OpenCV
Опубликовано · Report reply
Еще, совершенно случайно, было обнаружено, что печатные буквы можно удалить достаточно простым способом (маской из LSD). Правда и рукописный тоже подчищается, но это мелочи (можно чистить только нужные зоны). Не идеально конечно, прямые линии ("палки" от букв) от LSD в маску не попадают, поэтому удаляются только круглые (о, ф, е, я и т.д.)