
Smorodov
-
Количество публикаций
3 873 -
Зарегистрирован
-
Посещение
-
Days Won
346
Сообщения, опубликованные пользователем Smorodov
-
-
Это обращение матрицы, линейная алгебра, а не инверсия цветов.
-
Вначале уменьшить изображение до разумных размеров.
-
Бинарники тессеракта x64 для windows.
https://github.com/tesseract-ocr/tesseract/wiki/4.0-with-LSTM#400-alpha-for-windows
Бинарники OpenCV (не знаю какая разрядность, скорее всего x32 для windows.)
https://sourceforge.net/projects/opencvlibrary/files/opencv-win/3.2.0/
-
Наверное точка крутится вокруг минимума, медленно к нему приближаясь. А может датасет не перемешан нормально.
-
Ну можно посмотреть исходники GIMP-а.
У них там своя библиотека функций с использованием SIMD, но все можно выковырять при определенной настойчивости.
-
У вас же здесь цифры в прямоугольнике, прямоугольник белый, найдите его контур, впишите в прямоугольник (minarearect), вот вам и наклон.
Дальше повернуть изображение в обратную сторону.
-
Наткнулся на интересную статейку, не тестировал, просто чтобы не забыть.
https://blog.google/topics/google-cloud/google-cloud-offer-tpus-machine-learning/
Может кто пробовал, и поделится опытом ?
-
Да, правильно.
cvGetCentralMoment нужна когда нужно вычислить именно моменты как есть, например для поиска центра масс и осей инерции. -
Моменты используются внутри MatchShapes, на вход функция принимает контуры. Посмотрите здесь, вроде простой пример: http://derykstack.blogspot.ru/2014/07/example-using-matchshapes-in-opencv.html
-
Вообще можно тупо скользящим средним сглаживать.
У меня были случаи, что ошибка уменьшалась отскоками, падает, горб, снова падает, но уже ниже, опять горб, и так далее.
И тут уже сглаживание не поможет.
Причем интервалы между горбами одинаковые, и горбы эти не низенькие, а такие что вполне можно кнопку "стоп" нажать, так и делал, пока не передержал по недосмотру. Уменьшение шага только меняло период.
-
Да вроде в общих чертах похоже. Только классификатору передаются массивы (векторы) чисел а не числа по одному.
-
 1
1
-
-
Ну там не то что бы одно и то-же, но получается компактная область, которая и выделяется при обучении классификатора. Что внутри области - лицо, что снаружи не лицо.
При добавлении дополнительных измерений такие области можно отделить гиперплоскостью. Ну например как здесь:
-
1
-
-
Да, классификатору в принципе все равно откуда вы берете дескрипторы, ему важно чтобы классы были разделимы его средствами.
Он даже не должен знать набор признаков, который вы использовали, но важно использовать один и тот же набор признаков на всем множестве картинок с которыми вы работаете.
Извлечение признаков, переводит вашу картинку из одной системы координат в другую.
-
1
-
-
Да число, это число есть отклик признака. Каждый признак откликнется на изображение под ним по своему.
Будет что то вроде такого, если писать словами:
Изображение на 12% похоже на горизонтальный перепад яркости, на 5% на вертикальный, на 7% похоже на черную точку на белом фоне, на 4% на диагональный перепад яркости.
Вместе они опишут структуру изображения.
-
1
-
-
Это число выражает степень схожести изображения под признаком и самим признаком, наибольшее число будет если признак наложен сам на себя. Если глаза темнее щек, какая тут абстракция ? тут откликнется вполне конкретный признак (сверху черный, снизу белый).
-
1
-
-
По поводу изображения в серых тонах. Можно использовать и цветное (гонять по всем цветовым слоям), просто будет в три раза больше вычисленных признаков.
Значение признака = сумма всех пикселей под белой областью признака - сумма всех пикселей под черной областью признака.
Вообще говоря вы имеете дело с 250000 мерными точками.
Некоторые из них, это лицо. Задача классификатора провести гиперплоскость разделяющую лица от не лиц.
"Сильные признаки" - это совокупность "слабых" признаков. Прочитайте про статейку про adaBoost в теме которую я упоминал выше.
Просмотр идет от ступеней с максимальной вероятностью к уточняющим.
То есть идет окно вычисляем признак 1 - прошло, 2 - прошло, 3 - не прошло. отбрасываем - вывод - не лицо.
1 - прошло, 2 - прошло, 3 - прошло, - N - прошло принимаем - вывод - лицо.
Обучение одной ступени каскада выглядит примерно так:
То же самое, но представьте это в 200 000 мерном пространстве.
-
1
-
-
Детектор Хаара работает с изображениями в серых тонах, не с цветными.
Признаки - это всего лишь правило суммирования пикселей (если пиксель под белой областью + , если под черной - ). Максимальные значения будут если признак наложить сам на себя (попробуйте).
Совокупность признаков образует дескриптор, дескриптор является "выжимкой" полезной информации и ее унификацией. Мы не работаем с абсолютными значениями пикселей, а работаем со сжатым описанием области ("верх темнее низа" или "точка на темном фоне"). Это удобно.
Да они не 2х2, а могут быть разных размеров.
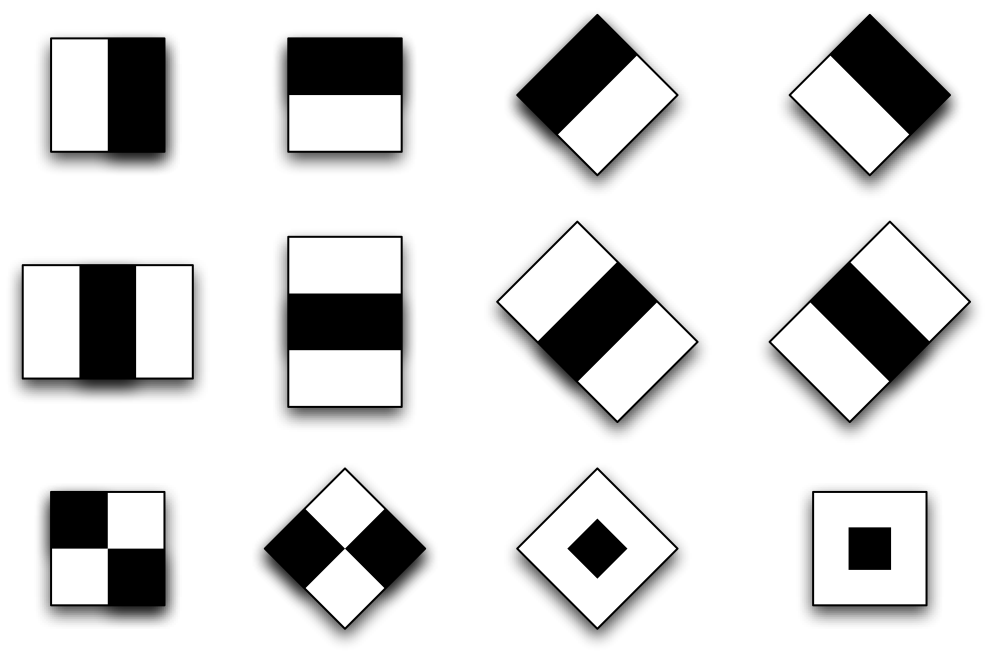
В окошке сканирования размещают все возможные комбинации этих признаков
каждый дает числовой отклик.
Итого, для каждого положения окна сканирования мы вычисляем числа для каждого признака . Признаков в окне может разместиться очень много каждый в каждой возможно позиции скользящего окна, во всех возможных масштабах, всех возможных типов. Вот для каждого варианта вычисляем число и кладем в вектор дескриптора скользящего окна.
После этот вектор идет на обучение классификатора.
Именно классификатор после обучения отделяет слонов от лиц. Но если нужны слоны, можно обучить классификатор и для них.
В детекторе Виолы Джонса используется каскадная система. То есть "сильные" признаки отсутствие которых сразу с большой вероятностью говорит "это не лицо", приверяются первыми, если они не обнаруживаются, процесс анализа окна прекращается и оно переходит на новую позицию (см. видео выше).
-
1
-
-
Вот здесь кое что есть:
Ну и отвечу на вопросы которые вы задали.
Для окошка сканирования 24х24, признаков Хаара, (прямоугольников с белыми и черными областями) может быть, насколько я помню, около 200000.
Так вот. Каждая позиция окна сканирования дает нам вектор и 200к чисел. И эти числа являются удобным представлением содержимого окна для дальнейшего анализа. Вычисляются признаки как вы и упоминали, суммируются яркости под светлой частью признаков Хаара и вычитаются не что под темной, это является мерой схожести куска изображения под признаком и этого признака.
Для поиска в различных масштабах, мы масштабируем окно сканирования, а не изображение.
Чтобы узнать есть ли в окошке лицо, нужно отправить извлеченный вектор признаков на классификатор. В OpenCV используется AdaBoost. Этот классификатор и решает есть лицо или нет в данной позичии окна сканирования.
Чтобы это все работало, классификатор вначале обучают.
-
1
-
-
Попробуйте код отсюда: http://git.net/ml/lib.opencv/2006-04/msg00196.html
Правда IplImage и C интерфейс уже очень сильно устарел, OpenCV сейчас работает с cv::Mat и C++ интерфейсом.
Скоро IplImage вообще уберут.
-
Посмотрите в этой ветке:
-
Если там скрыта синусоида, то надо делать разложение в ряд Фурье.
FFT даст пик на частоте синусоиды.
Статейка с Хабра: https://habrahabr.ru/post/219337/
Имел дело с подобными кривыми когда измерителем пульса баловался: HartRateMeasure.zip
Работа по которой делал: "Non-contact, automated cardiac pulse measurements using video imaging and blind source separation." легко гуглится.
-
2
-
-
-
Пробовали изображения бросать к экзешнику и запускать командной строкой из той же папки ?
Вообще странно, никогда таких проблем не было, может OpenCV собралось плохо?
-
А, ок, мой глюк.
Путь до изображения указываете полный?
Какой формат изображений ?
mat::inv() - не работает?
в OpenCV
Опубликовано · Report reply
https://ru.wikipedia.org/wiki/Обратная_матрица
Очень универсальная вещь, используется, в основном, при решении систем линейных уравнений.
Но далеко не только для этого.