
Smorodov
-
Количество публикаций
3 873 -
Зарегистрирован
-
Посещение
-
Days Won
346
Сообщения, опубликованные пользователем Smorodov
-
-
Да кривых рассеяния важно именно что там после рендеринга получается картинка очень близкая к исходному растру. А хранить нужно только эти самые кривые. Почему привел ? потому что это метод уменьшения избыточности изображения.
Сеперпиксели также позволяют уменьшить размерность задачи и поводить сегментацию изображения по меньшему количеству элементов. Можно провести каскадное преобразование или пропустить через классификатор и получить метки объектов.
Ваш метод безусловно интересен, и результаты очень хорошие, но пользы от количества предоставленной по нему информации не много.
-
Как варианты могут быть интересны:
Кривые рассеяния:
https://habrahabr.ru/post/156903/#first_unread
http://lcs.ios.ac.cn/~guofu/files/vectorization/SparseImageCurves.pdf
Суперпиксели:
http://ivrl.epfl.ch/research/superpixels
-
Да вроде его и собирать то не нужно, заголовки включил и ладно.
Вот тут посмотрите: https://eigen.tuxfamily.org/dox/TopicMultiThreading.html
-
Я говорил что метод тяжелый
") . У меня вообще прямолинейный реализован, тупо решает систему уравнений как есть.
. У меня вообще прямолинейный реализован, тупо решает систему уравнений как есть.
Есть разные оптимизации, но почти все будут требовать много ресурсов .
Вот список: http://www.alphamatting.com/eval_25.php
Все равно на CUDA будет лучше.
Еще можете попробовать robust matting: main.cpp но он тоже не быстрый 8 сек для 500x500 на Core i-7-4790.
Кстати, на нейронке тоже есть (и датасет автор обещает выслать
): http://www.cse.cuhk.edu.hk/leojia/projects/automatting/index.html
-
 1
1
-
-
Что то мне кажется что тут сегментация по цвету не прокатит, на примере автора вопроса даже участков кожи-то нет.
-
Ну если так, то остается еще GabCut и Matting оба метода тяжелые, но часто дают неплохой результат.
При крепил результат Matting, на входе trimap и изображение, на выходе маска.
Тут правда и обычный порог хорошо справится, но другие пример искать долго
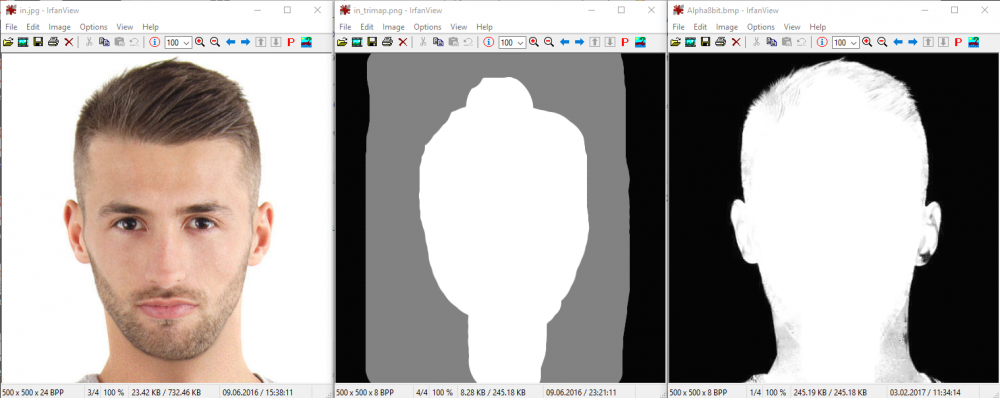
А вот, кстати нашел:
Есть довольно быстрые методы маттинга, в сети видел такие, но реалтайм не встречал, везде секунды и больше на кадр.
-
1
-
-
Ну так бы и сказали
Вот сюда попробуйте фотки загрузить и посмотреть результат: http://www.robots.ox.ac.uk/~szheng/crfasrnndemo (почему то у меня открывается только через tor браузер).
А вот исходники этой радости: https://github.com/torrvision/crfasrnn
-
Да, сильно смахивает на edge preserving smoothing группу алгоритмов по определению.
Посмотрите в сторону алгоритмов базирующихся на решении уравнений пуассона, здесь есть пример реализации суть в том, что можно выделить градиенты из изображения, отфильтровать их как нужно и восстановить изображение обратно. При подавлении слабых градиентов, изображение станет более "плоским".
Есть еще selectiveGaussian пощупать можно в gimp, оптимизированные исходники там-же, если по простому, то создается маска, выделяющая точки которые более чем на заданный порог отличаются от всех точек скользящего окна, также создается обычное размытое изображение, и последним шагом пиксели исходного изображения по маске заменяются на пиксели размытого изображения. Параметры метода: величина порога, и размер скользящего окна (размер окрестности).
По поводу фильтров еще есть такая популярная картинка, BLF это билатеральный фильтр, WLS это взвешенные наименьшие квадраты оба фильтра есть в OpenCV. WLS - аналог вроде называется FastGlobalSmootherFilter и находится в файле contrib/modules/ximgproc/src/fgs_filter contrib.
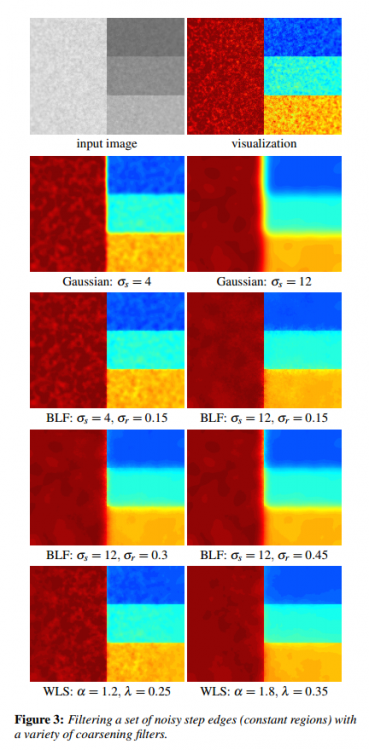
Ну и для коллекции: https://github.com/soundsilence/ImageSmoothing
-
Так там про нормирование в интервал [0:1] и не говорится, а говорится о взвешивании.
Если у нас открытое множество данных, то заранее невозможно установить рамки так, чтобы оптимально по распределению и умещалось в заранее заданный интервал.
Просто взяли некую площади за единицу, и посчитали соотношения.
-
Ну так взяли за единицу нечто среднее, вот и скачет в обе стороны, тем более площадь, там же квадратичная зависимость от стороны.
ЗЫ: А что за синий текст
?
-
Отдельная история.
Контора специально собирала (3ТБ данных), естественно они под NDA .
-
Добавьте в библиотеки imgcodecs (у меня называется opencv_imgcodecs310.lib ). Она была добавлена в третьей версии.
-
Простейший пример:
#include "opencv2/opencv.hpp" using namespace cv; int main(int argc, char** argv) { Mat img; img=imread("image.png",1); imshow("my image",img); waitKey(); return 0; }
А для вывод на форму посмотрите это: SimpleQTApp.rar
-
Лучше использовать новый интерфейс функций OpenCV (Mat вместо IplImage, cv:: вместо cv, короче c++ ).
Откройте стандартные примеры (папка samples) там достаточно кода чтобы понять что да как.
А не подключаться может либо из-за того что OpenCV построена без поддержки Qt, либо старые функции уже в другой либе.
-
Поддерживаю. Но думаю перестройка OpenCV решит текущую проблему.
15 минут назад, fotomer сказал:Если работаете на Винде, то есть большой смысл использовать Visual Studio как компилятор QT проектов. У меня в Студии плагин для работы с QT, все настройки OpenCV (хедеры и либы) указываются в студии, а Creator использую только для ваяния интерфейса окошек.
-
Зачем менять систему ? Просто в профиле проекта переключите конфигурацию, кстати она по умолчанию скорее всего x32.
https://forum.qt.io/topic/14753/solved-how-to-build-64-bit-application/7 пишут что Qt нужно перестраивать чтобы поменять разрядность проектов.
-
Я давно уже не работал с Qt, но помнится пересобирал почему то.
То ли окна не показывались, то ли вообще не собиралось.
Еще может быть что проект x64, а либы x32, тогда тоже они не прилинковываются.
-
1. OpenCV собран с поддержкой Qt ?
2. Отладочная конфигурация не увидит релизных библиотек (без буквы d в конце имени).
-
1
-
-
На CNN обучал на 6 эмоций точность на тестовой выборке ~87%, работает в реалтайме.
Правда много данных и долгое обучение.
Пробовал AAM, выдает не более 70%.
Посмотрите еще https://github.com/TadasBaltrusaitis/OpenFace там вроде AU встроены, правда этот функционал не тестил, использовал только landmark detector.
-
Если приведете несколько примеров изображений и опишите что Вы пытались делать, может кто и сможет помочь.
Например посмотрите как здесь делают: https://rdmilligan.wordpress.com/2015/03/01/road-sign-detection-using-opencv-orb/ правда тоже Хааром детектировали, а вот дальше извлекали ORB дескрипторы и сравнивали с шаблоном.
Здесь еще проект с исходниками: https://sites.google.com/site/mcvibot2011sep/home
-
1
-
-
Да нет, просто я подумал что можно искать по цвету, а после отсева по площади, по параллельности граней, еще каким нибудь признакам, уже подать вырезанные области на классификатор. SVM, нейронку, ну или какой нибудь еще для уточнения.
-
А без цвета, это принципиально ?
-
С VTK у меня не сложилось как-то, заморочно матрицами проекции управлять было, плохой осадок остался.
-
Может http://pointclouds.org/ ?
http://pointclouds.org/documentation/tutorials/correspondence_grouping.php#correspondence-grouping
Да тут наверное проще на шейдерах написать или взять какой нибудь фреймворк для отрисовки.
Недавно юзал этот: https://github.com/bkaradzic/bgfx правда не для точек, кросс-платформенный и вроде без лишних хвостов.

Алгоритм сегментации по принципу скользящего окна и вычисление контраста
в OpenCV
Опубликовано · Report reply
По классике для сравнения объектов, обычно выделяются признаки, совокупность которых, по сути своей, является компактным представлением класса объектов, позволяющим максимально точно различать эти объекты между собой.
Если мы имеем дело с лицами, то признаками может быть например словесное описание особенностей лица, если человек знает с чем имеет дело, то ему и не нужно описывать как выглядит лицо, так как большинство лиц похожи. А важна только информация, позволяющая выделить конкретного человека.
Классификатор, это такой инструмент, который позволяет вывести необходимые нам признаки, чтобы мы могли различать объекты, подавая на него новые данные. Могут быть как обучаемые, так и жестко заданные вручную. Обучаемые могут быть построены на основе простых математических правил (если a > 0.5 тогда это "кот" иначе "собака"), математической статистики (задаются распределения и выводится вероятность принадлежности объекта к заданному классу ("кот") ), или нейронных сетей (тоже бывают разные).
Как признаки, так и правила разделения классов могут быть как заданными вручную, так и обучаемыми на данных.
см. "собственные лица" (eigen faces) как обучаемые признаки, или SIFT, FAST, LBP, SURF и т.д. как универсальные синтетические признаки (созданы вручную).
Метки объектов, это просто их удобное для компа представление (0-фон, 1-кот, 2-пес).
Каскадное преобразование, я имел ввиду проводим одно и то же действие с одним и тем же изображением но в разных масштабах. Можно изменять масштаб после обработки, например суперпикселями, а после обратным ходом, объединив суперпиксели и передав метки с наименьшего масштаба наибольшему получить сегментацию для исходной картинки. Ну это просто как вариант.
После этого объединяем результат. Еще называется "пирамида".