
Smorodov
-
Количество публикаций
3 873 -
Зарегистрирован
-
Посещение
-
Days Won
346
Сообщения, опубликованные пользователем Smorodov
-
-
Можно попробовать сыграть на преломлении. Поясню. Если взять подложку с нарисованной сеткой, и сфоткать, затем поставить стекло и снова сфоткать. После этого наложить изображения и найти разницу. Конечно придется поэкспериментировать, но может сработать. По поводу размеров, вы же пишите что ряд фиксированный. Поставьте в соответствие каждому размеру площадь в пикселях.
-
Стенд всегда такой, освещение? Короче, среда управляемая нами?
-
Гляньте здесь: http://donvideo.ru/blog/29/ думаю с включенной HLC должно работать лучше, т.к. на фотках выше что с подсветкой, что без, для номера без разницы.
-
 1
1
-
-
На фотках верхняя без подсветки, а нижняя подсвечена ?
-
Возможно связано с засветкой. Ведь диафрагма открыта на полную. Номер покрыт световозвращающим покрытием и может просто слепить камеру. Да и изображение через широкую диафрагму по определению менее четкое.
-
Перенаправить вывод в линуксе можно стандартно:
SomeCommand > SomeFile.txtПодробнее тут:https://askubuntu.com/questions/420981/how-do-i-save-terminal-output-to-a-file -
Дык на чем остановились то ?
-
-
Не уверен что хуже, задавать размер тензора вручную, или мешать C и C++, но так-то теоретически возможно:
https://www.oracle.com/technetwork/articles/servers-storage-dev/mixingcandcpluspluscode-305840.html
Может оптимально будет просто записывать при заморозке еще один файл, с дополнительной инфой ?
-
Так там вроде как размеры тензоров при заморозке фиксируются, и надо самому их знать по модели. Вроде как получение размеров тензоров и не поддерживалось. Но тут у меня опыта немного, могу ошибаться.
-
В 06.09.2019 at 11:51, Nuzhny сказал:Smorodov, это то, что называется re-id. Кажется, что оно может плохо работать, ведь сеть обучается не различать отдельные объекты между собой, а отличать типы объектов. Кажется, что все люди будут близки друг с другом, машины друг с другом, а надо ещё и их различать между собой. Впрочем, я тут ещё не экспериментировал, надо попробовать, раз уж YOLO в проект проинтегрировано, благо и образец имеется.
Надо ещё из OpenVINO потестить, у них есть обученная модель на "Identify Someone in Different Videos". Но это опять таки же сеть специально обученная различать пешеходов между собой. Также там есть "face reidentification" - различать лица между собой.
Кстати, еще подумалось, ведь уровень абстракции сети растет от входа к выходу, то есть чтобы получить признаки для описания конкретного экземпляра объекта, нужно просто отрезать побольше выходных слоев.
-
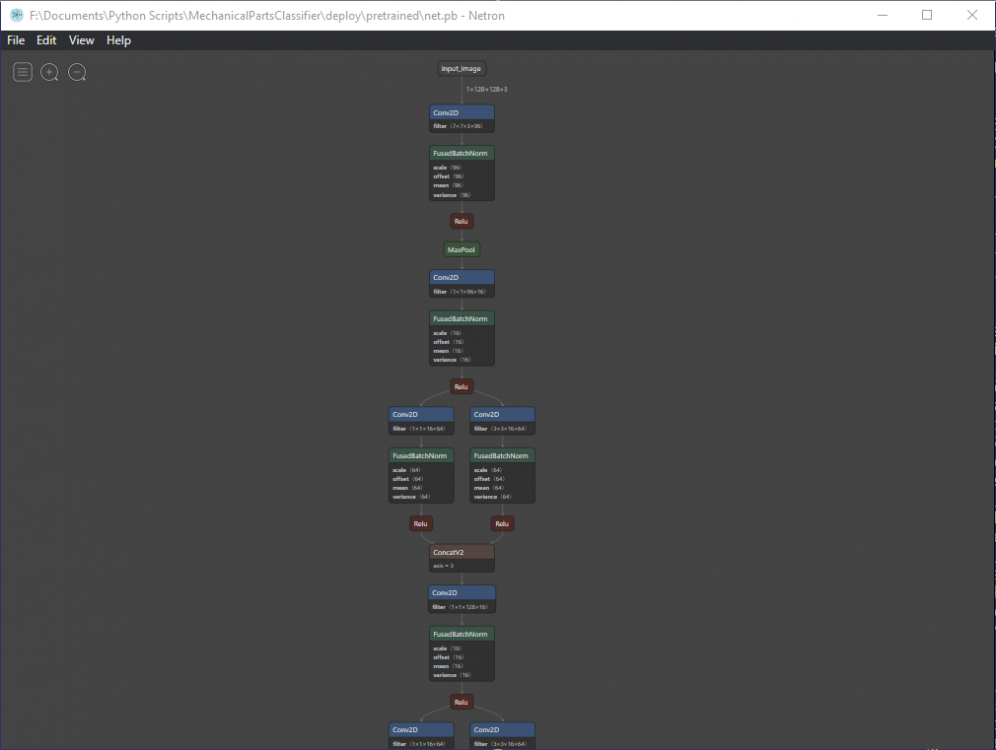
Подкину еще один скрипт, выдранный из работающего проекта. FreezeMe.py тут некоторых вещей нехватает, но может чем и пригодится. И еще, чтобы смотреть что записалось попробуйте Netron, я его как то уже упоминал.
-
 1
1
-
-
Ну тут от сети зависит, есть ведь сети для распознавания лиц, например. Что мешает обучить сеть на пешеходах под разными углами зрения, и научить извлекать признаки для различения их между собой. И соорудить каскад, тип объекта + дескриптор.
-
По поводу нейронок, согласен, с мелкими объектами их применять проблематично.
Но можно попробовать применить метод, похожий на распознавание лиц, когда вычисляют расстояние или угол между векторами, выдаваемыми сетью. Где то видел трекер, в котором используется подобная технология. Там берется что то вроде AlexNet и обрубается последний слой, и выходы предпоследнего слоя, используются как признаки для трекинга. Вот их и используют как часть метрики схожести, наряду с расстоянием и скоростью. -
Я не использовал питоновскую либу, но помнится намучился строить TF на MSVS, проект сейчас не нашел, было давно.
Но помнится, что там еще много чего надо было кроме DLL-ины.
Вот здесь посмотрите, может поможет: https://joe-antognini.github.io/machine-learning/windows-tf-project -
Там все на базель завязано, проекты тоже в нем собираются. Дело вкуса, но мне эта штука не нравится, и как решение, можно попробовать напрямую грузить замороженные модели прямо OpenCV-шным dnn модулем, либо преобразовать через ONNX в любой другой формат и опять же, либо через OpenCV, либо CAFFE, ncnn, .... или другой понравившийся фреймворк.
TF -> ONNX: https://github.com/onnx/tensorflow-onnx
Кстати, классная штука: https://github.com/lutzroeder/netron
И эта тулза может пригодиться: https://github.com/daquexian/onnx-simplifier
-
-
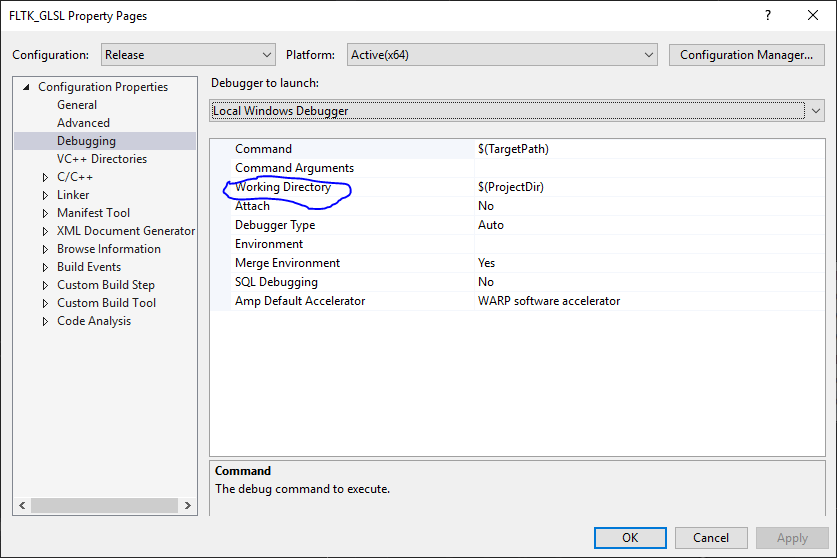
Здравствуйте, если запускаете под отладчиком, задайте путь отладки (где exe-шник лежит).
-
1
-
-
Используется еще вектор скорости. Предполагается что объекты инертны, и векторы скорости быстро не меняют.
Ну еще копайте разные фильтры Кальмана и иже с ними.
Есть еще наш с Сергеем Нужным проект: https://github.com/Smorodov/Multitarget-tracker
правда по коммитам сейчас он много больше его чем мой
")
-
Пожалуйста, пишите по сути, что-нибудь практически полезное.
-
Ну не факт
.
Наиболее частые ошибки:
не тот порядок каналов;
неправильная раскладка цветовых данных (чередующиеся или по плоскостям);
не вычтенное среднее, не тот диапазон (0-255 вместо 0-1).
-
-
Просто тут не будет
AAM , по опыту, довольно медленный.
ASM , как правило, быстрый, но дерганый, нужно сглаживать движение.
Посмотрите этот проект: https://github.com/TadasBaltrusaitis/CLM-framework/tree/master
Там есть и матлабовские скрипты для обучения моделей.
Может пригодится еще : https://github.com/patrikhuber/eos
-
1
-
-
Для начала соберите изображения, на которых сеть ошибается и дообучите сеть на них.
(лучше новые, собранные при реальной работе)
Можно просто дублировать их в датасете, чтобы встречались почаще.
Ну и повторять процесс, пока результат не устроит.
Поиск стекла на фотографии
в OpenCV
Опубликовано · Report reply
Если провести бинаризацию, может и не сильно, надо пробовать.
У меня этот метод давал неплохой результат: https://stackoverflow.com/questions/22122309/opencv-adaptive-threshold-ocr/22127181#22127181
Еще думается если найти фазовый сдвиг, то он тоже даст границу стекла.
Можно после бинаризации наложить изображения по И темные линии станут толще, затем инверсия, эрозия, и найти convex hull.