
Nuzhny
-
Количество публикаций
1 427 -
Зарегистрирован
-
Посещение
-
Days Won
176
Сообщения, опубликованные пользователем Nuzhny
-
-
Для начала - да.
Тут ещё вопрос - сколько ключевых точек будет на снимке и в этом месте на карте. Очень часто делают итеративно (кадр меньше карты, на нём ключевых точек меньше):
1. Находят все соответствия точек кадра к точкам карты, это может быть один ко многим (одно соответствие на кадре может соответствовать 0, 1, 2,... точкам на карте).
2. Находят область на карте, куда выпадает большая часть соответствий.
3. Если область карты по масштабу больше снимка, то повторяются шаги 1-2.
4. Если область карты по масштабу совпадает со снимком, то ищут уже соответствия методом, который ты привёл: один к одному, чтобы совпадали в обе стороны.
-
48 minutes ago, prim.ko said:Проблема тут скорей в том, что гораздо большую ценность имеет факт наличия объекта определенного класса, чем его форма ( для вычисления моментов ). Я думаю, что необходимо как-то перейти к относительной мере сходства между объектами. В качестве свойств объектов например вычислять центр масс объекта и использовать координаты центра масс на векторной глобальной карте и сегментированной картинке, и каким-то образом плясать от этого. Плюсом возможно станет избавление от слоев пирамиды.
Куда смотреть?
На пальцах: увидели объект А класса дом, увидели объект Б класса дом, рассчитали центр масс, сравнили расстояние. ищем что-то похожее в базе
Меня всё таки не покидает мысль о ключевых точках. Найти их на карте, хранить. Они же содержат в себе и масштаб также, часто точка+дескриптор - описывают целое озеро. Или вообще что-то типа MODS посмотреть.
-
15 minutes ago, mrgloom said:1. KCF сейчас топ трекер?
2. Если такие датасеты в публичном доступе как в пейпере social lstm?
1. Нет и никогда им не был. У него другие достоинства. Он быстрый! И может достаточно корректно определить факт пропажи объекта. Также видел проект, где KCF в качестве short-term tracker'а успешно заменил Лукаса-Канаде в составе TLD. И стало только лучше во всех отношениях. Думаю, что топ-трекеры надо искать на VOT.
2. Специально не искал, но должны подойти классические PETS или https://motchallenge.net/
-
Ммм, что фазовую корреляцию, что Лукаса-Канаде надо применять к исходным снимкам, до сегментации. Они полезны в качестве метода доуточнения позиции, найденной моментами.
Про моменты: ты можешь сохранять моменты не только изображений регулярной сетки как сейчас, а ещё и моменты перекрытий?
Другими словами, у тебя сейчас есть плавающее окно размером 256х256 с шагом 256 по вертикали и горизонтали - перекрытий нет, вся площадь покрывается. Может стоит сделать окно 256х256 с шаком 128 по вертикали и по горизонтали? Окон получится в 4 раза больше, но моменты же сравниваются всё равно быстро.
-
12 minutes ago, Artemtemtem said:Получается, чтобы мне сделать, например, детектор движения автотранспорта, мне нужны обучалки для легковушек, автобусов, троллейбусов, грузовиков, маршруток и т.д. Не уверен, как это можно сделать.
Нет, думаю, что в такой формулировке можно обойтись и без этого (хотя не помешает). Я больше занимался универсальным детектором, который для всего. А это и, например, такие видео как отсюда: https://github.com/utkarshtandon/GMCP-Tracker-Python-Implementation/tree/master/www
Там можно посмотреть parkinglot.mp4, petsvideolarge.mp4, tudcrossing.mp4. Желательно знать, сколько людей идёт, не путать их.
Если видео с вокзала, например как с PETS2007, то надо ещё определять оставленные сумки и чемоданы. Алгоритм вычитания фона на таких видео видит всё больше непрерывное поле с каким-то движением.
Кстати, я с содроганием вспоминаю ночные видео с автомобилями, где включённые фары портят всю картину своим конусом света. А для низковисящих камер ещё и засвечивать иногда могут.
-
12 minutes ago, mrgloom said:А кто нибудь пробовал трекеры на нейросетях типа
1. Я не пробовал, потому что практически всегда программа должна работать на ноутбуках и компах, где видеокарты не будет. А на CPU медленно.
2. В это теме всё таки не трекеры обсуждаются, а детекторы, в состав которых может входить Multitarget tracker, а по ссылке Singletarget tracker наподобие KCF или TLD. На практике это будет ну слишком медленно отслеживать сотни, а то и тысячи объектов.
3. Если говорить о нейросетях, то частью детектора может быть такой подход: Social LSTM. Вот его мне попробовать интересно.
-
Для меня эта проблема тоже явная. Чаще всего балансировка идёт между скоростью и качеством работы. И всегда скорость приоритетнее.
1. Мой Feintrack - это довольно старый детектор, ещё до появления OpenCV начат. Он ориентирован на работу на слабых процессорах, использовался ещё на Пентиум 4, умеет детектировать оставленные предметы. Но под твои требования не подходит.
2. UrbanTracker - хорошо, отличный подход, объединить неустойчивое вычитание фона и достаточно устойчивые точки. Никак руки до него не дойдут.
4. В Multitarget-tracker самый лучший режим - это включённый Лукаса-Канаде и KCF. Режим не идеальный, но жутко медленный на практике.
Там же я экспериментировал с комбинацией: детектор лиц (Хааром) + детектор движения с вычитанием фона. Получилось неплохо! Детектор срабатывает не всегда, но достаточно часто. Получается не терять лица, даже когда они поворачиваются в профиль на несколько секунд и другими системами теряются (тем же dlib).
Была надежда на GM-PHD, но она не оправдалась.
Вот. Теперь о перспективных вещах.
1. Я уже убедился, что нормально работать получится только зная тип объектов, которые планируется детектировать. То есть автомобили, пешеходы, лица, животные - всё что угодно. Но детектор должен понимать, что это один объект. Ладно ещё машины вдали, едущие параллельно. Но когда они в пробке и вплотную друг к другу? А ещё серые и в пасмурную погоду? Мне кажется, что там только распознавание по типу объекта поможет.
Далее люди крупным планом. У них руки, ноги, само тело - всё совершает постоянные движения в разные стороны. Как добиться того, чтобы на том же вокзале они не разделялись на кусочки и не сливались в одно? Я так и не добился от детектора нормальной работы, надо их (людей) распознавать.
Этот путь хороший, правильный, но медленный и будет работать только через N лет, когда мощности подтянутся. Чтобы мог детектор движения работать на 20 видеоканалах FullHD на одном сервере. Или по Тегре в каждую камеру и распознавать на них, а не на компьютере.
2. Второй путь - это сегментация всего кадра на регионы. И наложение этой сегментации на маску переднего плана.
Вот этот подход мне кажется намного более перспективным. Он быстрее будет распознавания и сработает с любыми объектами, даже неизвестными. Не обязательно даже делать сегментацию какой-то очень точной. Я сейчас посматриваю в сторону суперпикселей, их сравнения и объединения. Возможно, что в ближайшем будущем что-то появится и в Multitarget-tracker'е, если руки дойдут.
Это моё личное видение перспектив детектора движения.
-
 1
1
-
-
Продолжу рассказ. Собрать всё получилось, но, как мне показалось, на практике применить такую штуку не так и просто. И вряд ли сильно полезно.
Видно плохо, но видно, что снежинки могут "сбить" bounding box (а по факту модель из Гауссианов) с автомобиля или пешехода. Когда два пешехода или автомобиля рядом, то модель поначалу на них создаётся одна и она начинает "танцевать" где-то между ними. Понятно, что всё это подбирается и решается правильными порогами, но я на этом исследование темы временно закончу.
Во-первых, мне не очевидны плюсы с точки зрения точности.
Во-вторых, сам метод отбирает время у трекинга, который ещё будет идти после. На видео я его не включал, это только вычитание фона и его результат фильтруется GM-PHD.
Не уверен, что сделанное надо вливать в основную ветку MultitargetTracker'а, это как Smorodov скажет. Если интересно, то оформлю получше и сделаю дополнительной опцией.
-
1
-
-
1 hour ago, 2expres said:И все-таки я хотел бы получить более конкретный ответ по поводу быстродействия нейросети в данном случае.
Зависит от сети и оборудования. В любом случае сети практически без разницы сколько типов объектов распознавать: 2, 3, 5 или 100. На вход картинка, внутри выделяются признаки, а классифицирует лишь самый последний слой, который может состоять из одного нейрона.
1 hour ago, 2expres said:Как я понимаю, что это задача для одного компьютера, отрабатывать будет одна и та же видеокарта, поэтому предложенный мной подход должен работать.
Я думаю, что даже смена драйвера может сломать весь подход. Это происходит повсеместно и регулярно: выходит новая ААА-игра, она где-то глючит, неправильно отображается, медленно рендерится. И производители видеокарт оптимизируют драйвера, меняют рендеринг, картинка меняется. Я бы точно не затачивался под точное соответствие.
-
10 minutes ago, 2expres said:Интересно, сколько времени будет отрабатывать нейросеть сравнивая 300 возможных объектов?
Гораздо интересней, что она не будет этого делать. В разных вариантах может быть последний слой с 300-ми выходами. На каком выходе значение больше, тот и найден. Либо будет вообще один выход, значение которого будет рассматриваться на попадание в один из 300-т диапазонов.
Ещё есть более продвинутые варианты типа Faster R-CNN, которые состоят из 2-х нейросетей: 1-я говорит, что здесь вероятно есть объект, а вторая уже его распознаёт (если он есть). Что-то типа boosting'а.
-
On 27.06.2017 at 11:17 AM, 2expres said:Если объекты абсолютно совпадают по цвету, то можно выполнить предварительную свертку базы объектов и делать такую же свертку объектов на картинке. Далее производишь сравнение сверток. Это значительно ускорит программу. Я думаю здесь подойдет 16 разрядная свертка типа CRC 16, но лучше использовать 32 разряда(CRC 32).
Т.е. каждый объект будет представлять собой 4 байта. Тогда можно обрабатывать хоть все 60 кадров в секунду.
Я бы на такое рассчитывать не стал. Какая видеокарта как отрендерит - погрешности будут 100%.
40 minutes ago, msorokin said:Не подскажите более менее простую сетку для такой задачи?
Yolo оказалась не простой в настройке под Ubuntu Server
Предлагаю путь проще, сетка тут и правда не нужна. Что надо:
1. создать датасет из всевозможных значков и картинок, которые надо будет искать;
2. рядом с каждой картинкой создать текстовый документ, в котором указана область изображения, в которой его можно ожидать увидеть.
Далее берём картинку и для каждого шаблона делаем matchTemplate. Всё это можно распараллелить по ядрам просто одной командой openMP. По результатам уже смотреть.
-
Может быть, я на скорую руку делал.
-
Тогда такая штука как нейросеть может оказаться слишком тяжёлой штукой для такой задачи. Может так получиться, что простая корреляция с шаблоном сработает на отлично.
-
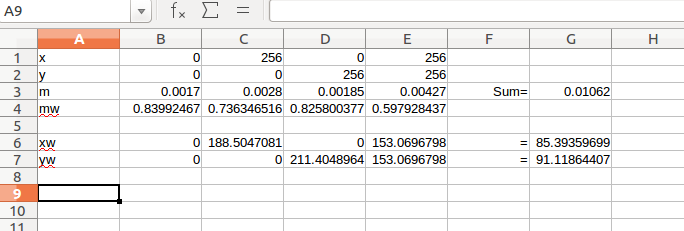
Тогда я проиллюстрирую то, о чём говорил. Берём метрики четырёх тайлов из левого верхнего угла, где находится красный квадрат (у меня там только первые знаки). Взвешенные координаты получились 85 и 91. Не точно, конечно, но и не так плохо.
Для такого метода надо искать не абсолютный минимум в одном тайле, а минимальную сумму из четырёх тайлов, образующих квадрат. При этом значения, которые больше некоторого порога учитывать в этой сумме не надо, как заведомо ложные. Они не должны участвовать ни в поиске минимума из четырёх квадратов, ни в вычислении взвешенной суммы. Если в моём примере взять такой порог за 0.003, то 4-й тайл учитывать не надо и значения получатся ближе к истине: х = 62, у = 70.
-
18 minutes ago, prim.ko said:В скринах выводится метрика в каждом из тайлов ( сравнивается с текущим кадром ).
Сейчас остановился на фазовой корреляции. Она дает отличные результаты в качестве "уточнения" области поиска абсолютных координат объекта.А, сразу не заметил. А где там находится истинное положение объекта?
Фазовая корреляция - это хорошо. Ещё как вариант можно брать то, что Szeliski называет Parametric motion в своей книге. Оригинал метода описан в статье Lucas-Kanade 20 Years On: A Unifying Framework и называется Inverse Compositional Algorithm. Отличная штука. Это если фазовая корреляция не подойдёт.
Нашёл исходники с Image alignment с помощью инверсного Лукаса-Канаде - вот. И видео с иллюстрацией есть.
-
1
-
-
7 minutes ago, msorokin said:Огромное спасибо. Можете мне подсказать как обучается данная нейронная сеть?
Вообще-то по ссылке последний раздел как раз и посвящён тренировке сети.
-
1
-
-
-
Непонятный результат.
Сделал возможность работать с прямоугольниками, а не просто точками, понастраивал всякие пороги. И... ничего внятного сказать не могу. Отсеивается не только шум, но и реальные объекты. И одновременно продолжает существовать шум, то есть сам фильтр его может оставить на следующий кадр, хотя его там вычитание фона уже и не находит.
Возможно, я неправильно выставил какие-то значения или ещё что-то. Мне эта тема ещё интересна, но сейчас времени совсем нет. Если интересно посмотреть на код, то он у меня лежит вот в этой ветке: пример в функции GMPHDTracker.
Чувствую, что надо набрать видео с ground truth и проводить полноценное тестирование, а не на глаз, как сейчас.
-
Я ожидал увидеть значения метрики в каждом из тайлов. Найти минимум, значения метрики в тайлах рядом. Если они совсем большие, то не учитывать. С остальными взвешивать.
Например, минимальная метрика равна n1 = 0.001, у соседа справа n2 = 0.002. У остальных соседей больше 0.1, т.е. больше некоторого порога, всех их не учитываем.
Тогда получим координаты:
x = x1 * (1 - n1 / (n1 + n2)) + x2 * (1 - n2 / (n1 + n2))
y = y1 * (1 - n1 / (n1 + n2)) + y2 * (1 - n2 / (n1 + n2))
Как-то так.
-
Да, именно это. Можно попробовать за положение тайла брать взвешенное значение окрестных к максимуму тайлов. Веса - как раз твоя метрика.
-
А ты можешь в каждом тайле нарисовать евклидову метрику, которая получается?
-
Автор кода GM-PHD мне ответил:
QuoteHi Sergey,
sorry for the delay, super busy right now. GMPHD and Hungrian+Kalman do not serve the same purpose if I'm not mistaken, since GMPHD does not handle the association problem. They're complimentary though, because GMPHD handles probabilistic noise (which is not the case for Hungrian, if I'm not mistaken again). In terms of questions that the algorithms answer, I would describe them (+KF), as:- my detectors give noisy measurements, not just in terms of metrics but also detection rate, which means that I have false positive and misses. GMPHD will try to solve the question : "how many targets do I really have there, and where are they, given those noisy inputs ?" It doesn't say how they associate with a previous measurement though, but it handles targets disappearing momentarily, targets spawning new targets, and false detections
- I get reasonable detection over time, but don't know how to match them with another. Then my understanding is that it's something that Hungrian will solve
- I get noisy measurements, in terms of metrics, for the same random variable. What's its real trajectory, and foreseeable future ? That's what the Kalman solves
In a nutshell (I don't have too much time unfortunately), it looks like GMPHD could be useful indeed, as a first step in your pipeline to try to clean up false detections, and the rest of the pipeline can stay the same
То есть GM-PHD не заменяет Кальмана+Венгерский, а используется перед ними, чтобы убрать лишний шум (лишние регионы после вычитания фона). Попробую так его и заиспользовать.
-
Тут проще всего заглянуть в исходники. Тогда будет понятно, что есть абстрактный класс-интерфейс и есть его реализация.
-
On 09.06.2017 at 5:55 PM, Nuzhny said:Есть такая штука, как Gaussian Mixture Probability Hypothesis Density for Visual People Tracking. Даже исходники есть: https://github.com/blefaudeux/gmphd
Что-то не очень понятно, как конкретно применять эту штуку. В связке Детектор-Венгерский-Кальман она какое место занимает? Замена связки Венгерский-Кальман? Вроде, нет. Просто Кальману? Тоже как-то не очень. В ветке gmphd добавил функцию-пример GMPHDTracker, в которой к детектору прикрутил тестовый фильтр из пример и.. как-то непонятно.
Современный детектор движения
в Обсуждение общих вопросов
Опубликовано · Report reply
Будет как-то так: